BT actually is not what I thought it was, i.e. reverse translating a large high-quality monolingual corpus in the target language to augment the data (although it seems Benjamin Marie & al. did exactly this for the low-resource scenario).
Duplicating the target set as done by Hoang & al., and augmenting the BT data with a tag should actually help the model make a difference, and two iterations is reasonable for further language pairs (that’s about one to two weeks) once the hyperparameters issue is settled and there’s no running aroung finding which ones do the job.
I need more details on the how to though. Let’s start with the hypothesis that you used “BT” tag token as stated in a previous article.
Then, did you use a specific option (inline tag, prefix…) to process it in Open-NMT train?
If so, did you develop a specific option in Locomotive (augmenter, transform) or are they simply specified as explicit parameters in the config file?
Yes, I used backtranslation first without tagging. But it seems you’re a couple months ago and you’re the one who gave me the idea that it can introduce distortion and bias. I started looking for a solution and came across the above research on how to avoid this.
I modified train.py in Locomotive to allow prefixes for source sentences (src_prefix) to be added to the config.json file.
So you started adding “src_prefix” to the list of onmt options available in train.py, then could specify for each source which prefix to prepend. The beauty in the prefix is that you can use it for multilingual training as well.
Did you do this for English-Russian too? And how does it work on inference then? Modifying LT to prefix the “q” value of the request?
Yes, that’s right, I did that for the last big EN-RU model as well.
In general for LT no modifications are needed right now. Just work as with a normal model.
In our inference queries there are no prefixes coming to the model, so the model is primarily focused on patterns that were in datasets without prefixes (i.e. original sentences, not back-translated or other language).
But if you train multilingual models like M2M or nllb, then you need to add support in Argostranslate and Libretranslate for src_prefix and tgt_prefix, and their post-processing, but this is another big story.
Well, then. Adding a few parameters to the already existing list is the kind of PR that I feel confortable with, so I will try to make time next week for adding to train.py.
RPE (the max_relative positions" default in openNMT is 0, putting it in the list should allow trouble-free absolute position encoding when those variables are left unspecified),
and the src_prefix value, with default “” @lynxpda Are you OK with it?
One more question, did you shuffle BT and original sentences on EN-RU?
Thanks for the train.py, I can make my PR compatible with yours to come.
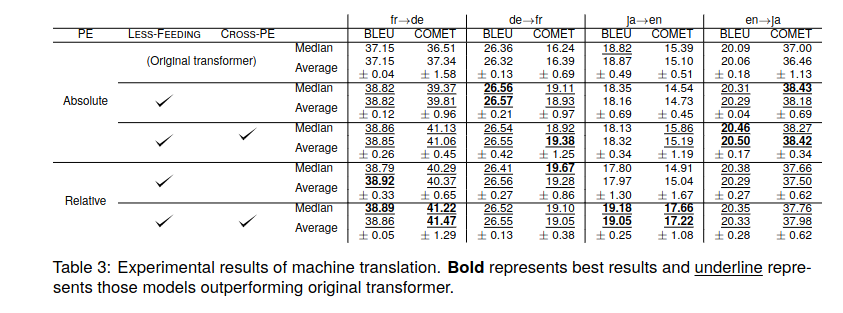
I manually evaluated RPE for effect. On one hand, it enhances fluidity a lot, but on the other, quite a few small tokens (adverbs, prepositions) are considered useless and eluded even when they aren’t, overall show litlle to no improvement. In highly intricate sentences with verbs at the end, the verb is either relocated (good), replaced (hum) or eluded (bad).
A fix may be to increase max_relative_positions to 32, which is neutral in terms of parameters and should work when syntax is utterly different (if you have the issue with finno-ugric languages, you may try). Another fix may consist in switching the activation functions, what you did. Smoothing labels some more (0.125) may also be a solution, I found that changes between relu-activated models and gelu-activated ones where similar to those I saw when dabbling with label smoothing (although gelu made classes more blurry, not less…)
RPE models converge slowly (20% slower than absolute PE), so I still can’t say whether and which gated activation works best. Training parameters have reached a new high, then they also had with RPE which turned out to be a pie in the sky.
Read your train.py, lots of changes! Smart idea to use weights and let onmt shuffle the sources for you.
Do I have to prefix all data (that’s what you do in the mulitlingual config), or only the back-translated one?
One thing in the end : the “package_slug” variable put all the package files into an eponymous folder, and allowed for clean install among other language pairs. Maybe not using it anymore explains the install issue I’ve had with your model.
I was actually just making changes and using a fairly old version of Locomotive (December 2023).
I added the src_prefix tag only back-translated sentences.
By the way, this kind of back-translation trick helped to train a fairly high quality model for Vepsian with only 3k pairs of parallel text sentences and 125k sentences in Vepsian only.
Hello,
Did you update OpenNMT-py and CTranslate2 to the last available versions in the course of your modifications (maybe to turn RoPE on)?
OpenNMT has implemented flash attention by default in the last months, that speeds up cycles and optimizes memory quite a lot.
They also implemented cuda12 if you have it installed (I do).
This is readily operable, only requires a change in the requirements.txt and pip upgrade.
Also, the byte fallback option is for translating as is anything that comes OOV, isn’t it?
On the issue of hyperparameters, once implemented correctly, silu/swiglu and geglu have pretty much the same effects as deepening on the COMET score. I still have to see what they actually yield in practice.
I am more skeptical about RPE. Upon second review, I was told it had shown no overall improvement. Since RPE 20 or 32 only improved COMET significantly at an early stage of training, and trained more slowly, I think of either doing without it or using RoPE, but for that, I need to have a configuration that’s as stable as possible.
Did you calculate COMET score for two models that would have the same dataset and training parameters but would only differ between PE and RoPE?
I’ve done it for PE and RPE, and in spite of a slight improvement, the comet-compare does not consider it to be statistically significant (9-16% of sentences are worse off, 14-30% better, the rest are the same). System scores show a difference between 1 and 4/10,000.
I didn’t make that comparison on COMET between PE and RPE. In those preprints that were about RPE/PoPE, there is mention of a slight improvement, which is the only reason why I applied them. I don’t think we should expect significant improvements in the model, especially on sequences up to 512 tokens (our case).
OK.
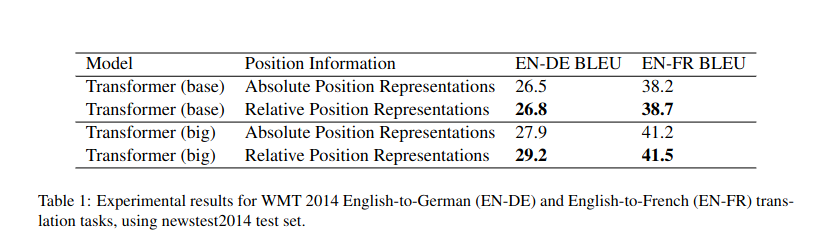
The first paper evaluates BLEU. On devtest, I get same BLEU (44.5) for all. On dev, absolute (61) is in the middle of RPE20 (56) and 32 (65)…on the reliability of BLEU.
The second one states that while there’s an improvement on short sentences, long sentences are left worse off with RPE.
Training data (especially subtitles and NNLB) contains quite many short sentences, hence the improvement in training metrics.
Flores datasets are closer to real life documents with more long sentences, therefore they cancel that bias.
Maybe RoPE has the better of both…
I have scripted backtranslating the source for use in the reverse direction, but once launched it looks like translating the 25 millions sentences will last forever (2 to 3 weeks).
I used the same translation functions used in eval.py to translate the flores dataset. But, since loading 25M sentences at once does not work, I reversed the loops to translate one sentence at a time. GPU seems quite busy at around 50-70.%, VRAM is less than a GB, so there may be some room for speeding it up. Any idea how ?
Also, the silu/swiglu fonction worked when completely implemented. Score are quite like GeGLU, I have to try both without RPE to confirm : COMET above 0.89, BLEU devtest at 42-44, BLEU dev 60 to 73 (close to google’s 75).
In live translations, some features that I had only seen in DeepL before appeared with gated activation. Since there’s a convolutional element in the ff it is not completely surprising, but there is still some way to go regarding fluidity and word registry. And the advantage is not decisive.
Very interesting! Can you tell me, if not secret source of data for back translation?
for my needs I took wikipedia, several news resources and open access books with open license and several technical sites for domain adaptation.
Next, I separated the texts into separate sentences (each with a new line) by myself using a script.
And what model do you use for back translation? It took me 3-5 days to translate 25M sentences with a 159M parameter model (20 encoder layers and 6 decoder layers, model quality is important but not crucial). And that’s on two RTX 3060s. I used Libretranslate API for translation and translated in batches.
Here is the script if it helps somehow:
“.env” - customization variables
“BT_libre_transl.py” - the back translation script itself
“generate_translation.py” - just an imported module for working with the API
“split_to_sents.py” - script for splitting text into sentences
I got the highest speed by running a different LT service on each individual video card and accessing each service in 2 threads with back translation, each LT on its own port.
Additionally, you can speed up by running additional LT on the processor.
You can also accelerate by reducing the size of the model.
P.s. the script immediately generates source.txt and target.txt files.
p.s.ps. I remembered, there is one more trick to squeeze a little more out of the model. If you train with an effective batch size up to 200k, then when the model has already stopped improving characteristics, we stop training, and continue it from the last checkpoint, but with an effective batch size of 400k and again until the stop of improvement (decrease) valid/ppl. (here you can put validation and saving models number of steps proportionately shorter).
A slightly more complicated option is to continue not from the last checkpoint, but from the averaged checkpoint averaged.pt (by renaming it). But then you need to manually set the learning rate = e.g. 1e-4 , because the optimizer state in the averaged checkpoint will be reset.
Thanks for the script, I saw you used chunks, so I did too.
I modified the function I developed for eval.py to prefix and translate sentences into a file, only thing was, when the sentence list reached several hundred thousands, cuda memory overflowed. Then, one sentsentence at a time was under optimal, around 60k sentences an hour.
The function is more straightforward than the api, with chunks of 5k sentences, it prefixes and translates around 600k sentences an hour. With chunks of 50k, 700k sentences. I tried bigger chunks earlier, it was slower, and unstable.
For now, i am just looking forward to backtranslate the dataset (see above) in order to apply the findings from that article you sent me.
I’ll send you the script when it will really have translated 25M sentences.
Another detail: upon trying to optimize the script, i noticed the “max-batch-size”, which i was tweaking with to optimize VRAM use, wasn’t neutral regarding translations’ quality. So i checked the parameter in ctranslate, argos and LT… default is 32, no such argument in LT… but in eval.py it’s 16. I have to reassess at least the variants I tried of RPE.
About “squeezing all you can from the model”, i agree and disagree. There is a known phenomenon in ML where as variance (measured by ppl) decreases while training, bias towards the training set increases. I noticed the increased bias in manual evaluation, but am still wondering how to make it visible in a metric, and as long as i have to include a fair amount of social media and web junk to pad the dataset, that’s trouble.
There is no statistically significant difference between evaluations using a max-batch-size of 16 and 32. Good news, because there were visible alterations with a 64 value, but I can postpone fixing eval.py for now.
Shaw20 is slightly superior to Shaw32 on a deep models with relu activation. Must be the same for gated activations, I’ll tell later.
Both gated activation functions are unstable with absolute position encoding, training collapses around 12k-14k steps, GeGLU trains for a while longer than SwiGLU, but I still have to make sure that writing the “max-relative_positions: 0” line in the onmt_train config file does train models with classic activation. Check in progress.
One question about training with backtranslation : do I have to update the control symbols in train.py before I do train a model with original dataset alongside BT dataset?
Unfortunately didn’t quite understand the question… If you mean additional control tokens for back translation labeling, then yes. They need to be added to the vocabulary and the SPM model.