Well, I really wonder how @lynxpda can train with an updated CTranslate2.
I tried every possible combination of torch+cuda, onmt-py and ctranslate2 between the ones used in Locomotive and the most recent. Best case scenario training breaks at validation steps with the following error cascade (worst case scenario, training begins with error cascade -most cases- or cuda is available but does not work).
It doesn’t matter what script I use, what data, from scratch or not… this may be caused by the “filtertoolong” transform inserted in the onmt configuration, but I am unsure what to do about it.
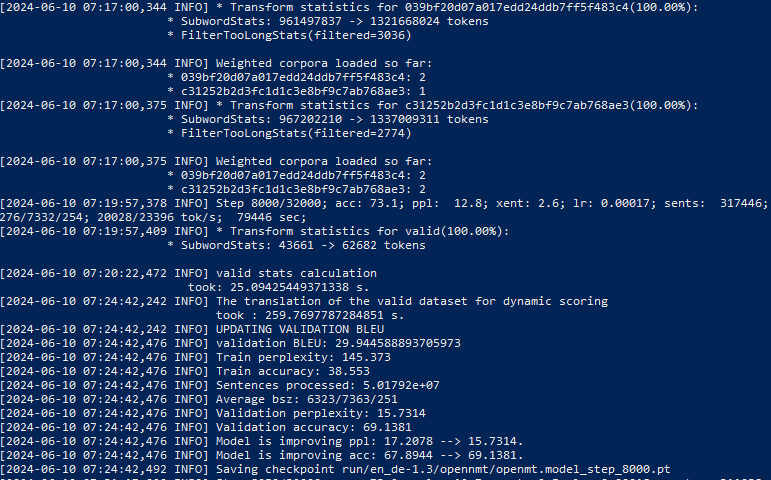
[2024-06-11 09:42:02,000 INFO] Start training loop and validate every 100 steps...
[2024-06-11 09:42:02,015 INFO] Scoring with: ['sentencepiece', 'filtertoolong', 'prefix']
[2024-06-11 09:48:24,332 INFO] Step 50/32000; acc: 0.4; ppl: 31126.4; xent: 10.3; lr: 0.00000; sents: 295284; bsz: 6628/7296/236; 21670/23854 tok/s; 382 sec;
[2024-06-11 09:53:54,287 INFO] Step 100/32000; acc: 4.7; ppl: 25540.5; xent: 10.1; lr: 0.00000; sents: 292443; bsz: 6604/7244/234; 25018/27441 tok/s; 712 sec;
[2024-06-11 09:54:36,382 INFO] valid stats calculation
took: 42.094335317611694 s.
Traceback (most recent call last):
File "C:\Program Files\Python39\lib\runpy.py", line 197, in _run_module_as_main
return _run_code(code, main_globals, None,
File "C:\Program Files\Python39\lib\runpy.py", line 87, in _run_code
exec(code, run_globals)
File "C:\Program Files\Python39\Scripts\onmt_train.exe\__main__.py", line 7, in <module>
File "C:\Program Files\Python39\lib\site-packages\onmt\bin\train.py", line 67, in main
train(opt)
File "C:\Program Files\Python39\lib\site-packages\onmt\bin\train.py", line 52, in train
train_process(opt, device_id=0)
File "C:\Program Files\Python39\lib\site-packages\onmt\train_single.py", line 238, in main
trainer.train(
File "C:\Program Files\Python39\lib\site-packages\onmt\trainer.py", line 332, in train
valid_stats = self.validate(
File "C:\Program Files\Python39\lib\site-packages\onmt\trainer.py", line 420, in validate
preds, texts_ref = self.scoring_preparator.translate(
File "C:\Program Files\Python39\lib\site-packages\onmt\utils\scoring_utils.py", line 111, in translate
_, preds = translator._translate(
File "C:\Program Files\Python39\lib\site-packages\onmt\translate\translator.py", line 494, in _translate
for batch, bucket_idx in infer_iter:
File "C:\Program Files\Python39\lib\site-packages\onmt\inputters\dynamic_iterator.py", line 341, in __iter__
for bucket, bucket_idx in self._bucketing():
File "C:\Program Files\Python39\lib\site-packages\onmt\inputters\dynamic_iterator.py", line 286, in _bucketing
yield (self._tuple_to_json_with_tokIDs(bucket), self.bucket_idx)
File "C:\Program Files\Python39\lib\site-packages\onmt\inputters\dynamic_iterator.py", line 247, in _tuple_to_json_with_tokIDs
tuple_bucket = process(self.task, tuple_bucket)
File "C:\Program Files\Python39\lib\site-packages\onmt\inputters\text_utils.py", line 95, in process
transf_bucket = transform.batch_apply(
File "C:\Program Files\Python39\lib\site-packages\onmt\transforms\transform.py", line 232, in batch_apply
batch = transform.batch_apply(
File "C:\Program Files\Python39\lib\site-packages\onmt\transforms\transform.py", line 70, in batch_apply
example = self.apply(example, is_train=is_train, **kwargs)
File "C:\Program Files\Python39\lib\site-packages\onmt\transforms\misc.py", line 56, in apply
or len(example["tgt"]) > self.tgt_seq_length - 2
TypeError: object of type 'NoneType' has no len()
Total checkpoints: 0