I’ve heard reports that the German translation quality isn’t very good. I think English-German is one of the most widely used language pairs so training improved models would be worth working on.
1 Like
Definitely a popular one.
1 Like
Lately I’ve been working on trying to improve the en->it model, but I’ve been finding it difficult to beat the current one.
One of the things I don’t quite understand is why the transformer struggles so much with single word translations. It can translate long ones, but sometimes something trivial such as “hello” gets translated as “ciao ciao” or some other repetition.
I’ve included dictionaries (multiple ones), to make sure I cover most single word sentences.
I’ve tried repeating single word datasets with more frequency to reinforce the learning.
I’ve tried adding EOS tokens.
Nothing seemed to help (consistently anyways).
I’ve found that people suggested using a straight dictionary lookup for single words because of this issue.
It’s also weird sometimes that “hello” translates as “ciao ciao”, but you add a punctuation (“hello.”) and suddenly the output is correct.
1 Like
Have you tried increasing the weight of the dictionaries (2-3 times more samples) and the size of the model?
Perhaps the number of individual words from the dictionary is too small relative to individual sentences and the transformer cannot capture statistical significance.
Plus, the capacity of the model may not be enough for memorization.
p.s. This is just a theory. In the Ru and Et models (still being trained, at the stage of the second iteration of reverse translation), I have not yet encountered this, although there may not have been enough checks.
Added: in many languages one word can have many meanings and translations, as I understand it, the most probable one is now being displayed. Maybe you can make it so that when you enter one word or phrase, say up to 20 characters, the top 3-5 options are displayed. I think transformers allow you to implement this.
Added2: I also filter all the others by length from 20-30 characters, as a result, individual words and phrases remain for learning only from the dictionary.
I hope this helps somehow.
Added3: I apologize, I didn’t read carefully that they already tried to increase the weights (number of samples).
2 Likes
Two things I have noticed on German translation with the 1.0 model
- somme pretty daily used tokens missing, such as “Lok” not being translated)
- some currently agglutinated words translate separately
German is actually quite regular (if not simple), both grammaticaly and semantically.
For the same meaning, one word will be used in a context, another in another context (in English it unfortunately often comes down to style), so a dataset of good quality and suficient size should do the trick.
2 Likes
I’ll try to retrain the German models. I want to see what effect can be achieved by tagging mined bitexts (CCMatrix).
2 Likes
Hello,
Began working on it a week ago. Instantiated Locomotive on Windows using a V100 GPU. Tested various parameters, ans so far, my results yield more questions than answers ![]()
- What shall I maximize? BLEU or accuracy?
I obtained the highest BLEU (51.0382) on my vanilla 5k steps trained with 10M sentences from the EU corpora (DGT, EuroParl, …), accuracy was 52.48 and perplexity 41.65
On the other hand, training for 50ksteps and adding as much trivia from CCMatrix and OpenSubtitles sunk the BLEU to 43.4752, but raised accuracy to 73.8118 and minimized ppl to 12.0746
Other questions follow…
2 Likes
Hello!
Can you attach train settings?
I think the number of training steps should only be discussed in relation to the effective batch size (number of GPUsaccumbatch_size).
The first thing to focus on is valid/ppl (less is better). I think a good indicator on FLORES200 (default in Lokomotiv) valid/ppl would be less than 11 (the final achievable score depends on both the training data set and the size of the model.).
It’s better not to focus on accuracy.
The BLEU assessment is difficult to navigate; in my opinion, valid/ppl correlates very well with subjective quality and does not have such a spread when training different models.
2 Likes
OK, I am not sure what the abbreviations stand for… the Locomotive logs feature several such values
For instance, the checkpoint after the first 5k steps of my vanilla model displayed
valid stats calculation (19.156410932540894 s.)
translation of valid dataset (364.9110949039459 s.)
validation BLEU: 2.6792101151198695
Train perplexity: 119.19
Train accuracy: 37.0487
Sentences processed: 8.99618e+06
Average bsz: 6291/6631/225
Validation perplexity: 41.6536
Validation accuracy: 52.4844
Model is improving ppl: 43.5846 --> 41.6536.
Model is improving acc: 51.5805 --> 52.4844.
Config file follows
{
"from": {
"name": "German",
"code": "de"
},
"to": {
"name": "English",
"code": "en"
},
"version": "1.0.2",
"sources": [
"file://C:\\Users\\NicoLe\\Nopus",
"opus://ELRC-417-Swedish_Work_Environ",
"opus://ELRC-1088-German_Foreign_Offic",
"opus://ELRC-1089-German_Foreign_Offic",
"opus://ELRC-1090-German_Foreign_Offic",
"http://data.argosopentech.com/data-wiktionary-en_de.argosdata",
"opus://ELRA-W0301",
"opus://DGT",
"opus://Europarl",
"opus://EUbookshop"
],
"save_checkpoint_steps": 250,
"valid_steps": 250,
"train_steps": 5000
1 Like
From what I see:
Validation perplexity: 41.6536- you should focus on this parameter. The lower the better. Below 12 is already good.- Everything that is not explicitly written in config.json - the default parameters are taken from the
train.pyfile - Apparently, you are training on one GPU, which means the effective batch size = 188192 = 65536 (in train.py:
'batch_size': 8192, 'accum_count': 8,)
Personally, in my experience, a larger batch size increases the quality of the model, but with diminishing returns. For Transformer BASE models, I got the maximum quality with an effective batch size of 200k (in your case, you can set'accum_count': 24). - With an effective batch size of 200k and a large dataset (more than 50M pairs of sentences), 70-100k training steps are usually sufficient. At 65k - I think about 200k steps.
- You can also increase the size of the model itself (if the dataset is large enough and of high quality, this makes sense):
'transformer_ff': 4096 - increases the ff layer, judging by the preprints of the articles and my observations, it gives the greatest quality gain relative to increasing the size of the model.
'enc_layers': 20 increases the number of encoder layers, together with increasing the ff layer gives the greatest gain in quality.
I provided the calculator and parameters in this post:
If you increase the size of the model, do not forget to use ‘batch_size’ and ‘accum_count’ to set the effective batch size so that everything fits in your VRAM.
3 Likes
Also, I followed on your attached post : in my current run, I tweaked train.py to implement these parameters
'enc_layers': 20,
'dec_layers': 6,
'heads': 8,
'hidden_size': 1024,
'rnn_size': 1024, #figured it should equate hidden_size... ok?
'word_vec_size': 1024, #the same...
'transformer_ff': 4096,
and overflowed the VRAM, so I halved “batch_size” to 4096 and doubled “train_steps” to 40k… but from your last post I realize I should raise ‘accum_count’ instead.
I also consider writing a “middling” filter to allow for expurging top and bottom percents of a corpus (your issue on CCMatrix) using Locomotive.
It is better not to touch the train.py file, but simply add changeable parameters to config.json.
And regarding batch size, decreasing it with increasing number of steps is not equivalent to training with a larger batch size. If you reduce batch_size, then it is better to increase accum_count by the same amount, then these will be equivalent settings.
Also, with 'enc_layers': 20 it is better to set
'hidden_size': 512,
'rnn_size': 512, #figured it should equal hidden_size... ok?
'word_vec_size': 512, #the same...
Otherwise it will be a REALLY big model)
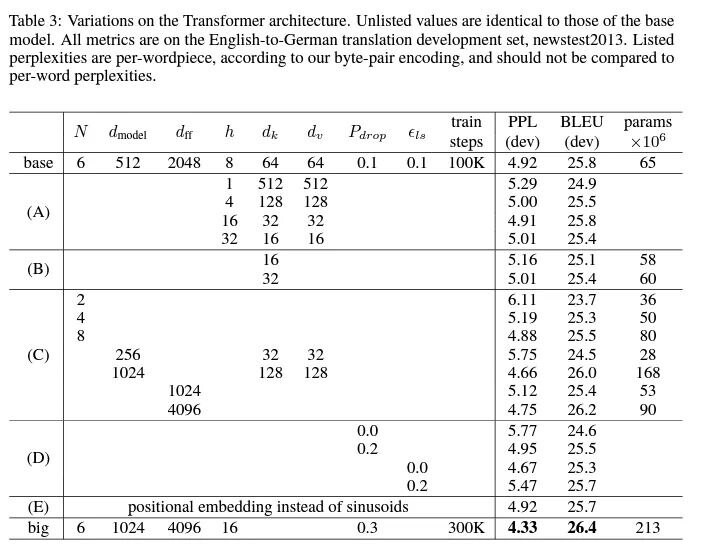
in the table, the hidden size for the “DEEP” 159M model is 1024, therefore the values.
Does it really not matter?
Or matters less?
In which table did you see this? Can you provide a link?
This is a clear mistake.
The hidden_size (d_model) parameter is a very important parameter, as far as I understand, it determines the dimension of the vectors and indirectly affects the size of the attention heads.
However, I don’t remember using a deep layered model at this size, it would have turned out too huge.
Perhaps you mean Transformer BIG, which I referred to in earlier posts, but the number of encoder layers there did not exceed 6 (vanilla BIG transformer).
However, it later turned out that the BASE model can be scaled not only in width (ff, d_model) but in depth, which also has its advantages.
At the level of intuition, if we completely simplify the architecture to a couple of phrases:
- The transformer consists of two large blocks - an encoder and a decoder:
- The encoder processes the input sequence and encodes it into an internal attention-aware multidimensional representation.
- The decoder turns the multidimensional representation into a sequence of tokens (then and words) and works like ChatGPT, producing the most likely next token depending on the previous ones and data from the encoder.
- The encoder and decoder consist of many identical layers knitted together.
- The size of each layer, in turn, is determined by the hidden_size and feedforward parameters (the number of attention heads does not affect the size, but depends on the hidden_size size):
- hidden_size is actually the dimension of the vector that encodes the tokens/sequence; the larger the dimension, the more accurately the coordinates of words/tokens in space can be conveyed. You can more accurately take into account synonyms, meaning, context, etc.
- feedforward in each encoder/decoder layer has one layer and is connected to the attention layer (hidden_size) at the output. It introduces nonlinearity into encoding/decoding and probably has a partial memory function (I heard that in ChatGPT it is responsible for memory and conversion)
- the number of attention heads, everything is simple here, the optimal number of heads = hidden_size/64
- The number of encoder layers can be changed, and the size of the model will grow almost linearly, depending on the increase in the number of layers.
- It is better not to touch the number of decoder layers; they affect the quality of the model almost in the same way as the encoder layers, but the performance of the model during inference drops very much.
- Increasing feedforward from 2048 to 4096 (or 8192) gives the greatest increase in quality relative to the increase in model size.
- Increasing the number of encoder layers from 6 to 20 also significantly increases the quality, with a linear increase in the size of the model.
- Increasing hidden_size significantly improves quality, but at the same time the increase in model size is almost exponential.
Accordingly, we have to look for compromises between these parameters depending on the task and the amount of data.
p.s. I might have oversimplified something.
2 Likes
Maybe this will help, on one GPU I would train config.json in this configuration:
{
"from": {
"name": "German",
"code": "de"
},
"to": {
"name": "English",
"code": "en"
},
"version": "1.0.2",
"sources": [
"file://C:\\Users\\NicoLe\\Nopus",
"opus://ELRC-417-Swedish_Work_Environ",
"opus://ELRC-1088-German_Foreign_Offic",
"opus://ELRC-1089-German_Foreign_Offic",
"opus://ELRC-1090-German_Foreign_Offic",
"http://data.argosopentech.com/data-wiktionary-en_de.argosdata",
"opus://ELRA-W0301",
"opus://DGT",
"opus://Europarl",
"opus://EUbookshop"
],
"batch_size": 4096,
"accum_count": 25,
"warmup_steps": 16000,
"train_steps": 100000,
"learning_rate": 2,
"vocab_size": 32000,
"avg_checkpoints": 8,
"src_seq_length": 185,
"tgt_seq_length": 185,
"enc_layers": 20,
"dec_layers": 6,
"heads": 8,
"hidden_size": 512,
"word_vec_size": 512,
"transformer_ff": 4096,
"save_checkpoint_steps": 1000,
"valid_steps": 2500,
"num_workers": 6,
"valid_batch_size": 64,
"bucket_size": 32768,
"early_stopping": 0,
"dropout": 0.3
}
Oops, I misread the parameters. Training with “hidden” = 1024 exploded in flight, with a validation pppl at “nan” after 4k steps and yielded a 450M model.
Thanks for the explanation, everything is clear now.
I run a new train.py.
"vocab_size": 32000,
"save_checkpoint_steps": 500,
"valid_steps": 500,
"train_steps": 20000,
# "batch_size": 4096,
"accum_count": 25,
"enc_layers": 20,
"transformer_ff": 4096
NB : Change the “train_steps” value then run it again, training resumes from 20000 to the value.
Sorry, I didn’t quite understand.
train_steps is the total number of training steps.
Yes, I forgot to say, if you change parameters that affect the size of the model or the learning rate, then the training needs to be restarted from scratch. (other parameters, such as batch size, accum, training_steps, can be changed during the training process.)
@NicoLe Then I will not train the EN_DE model, so as not to duplicate the work.
I am ready to assist in any questions that arise.
2 Likes
I realized it too.
Upon running 1.0.4, I lowered batch size and raised train steps values.
Training resumed where it had ended. But after adding a source, I had to retrain from scratch.
I will keep you posted about the results.
2 Likes