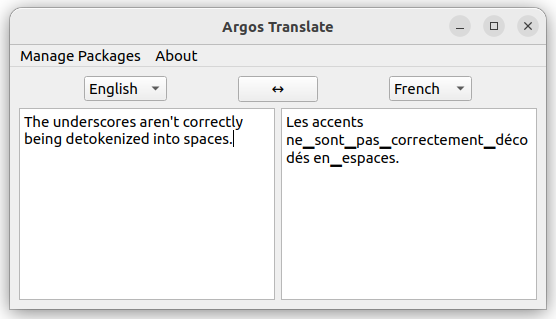
When using Libretranslate, I noticed this problem: if some characters are not in the vocabulary, they are simply absent in the translated text. This often spoils the translation. For example:
Source text:
Origami (折り紙, Japanese pronunciation: [oɾiɡami] or [oɾiꜜɡami], from ori meaning “folding” , and kami meaning “paper” (kami changes to gami due to rendaku)) is the Japanese art of paper folding. In modern usage, the word “origami” is often used as an inclusive term for all folding practices, regardless of their culture of origin.
Translated text:
Оригами ( Or, японское произношение: [ohorigelami] или [ohori Orgelami], из ори означает «сворачивание», а ками означает «бумажный» (kami Changes to gami by rendaku)) — японское искусство складки бумаги. В современном использовании слово «оригами» часто используется в качестве инклюзивного термина для всех методов складывания, независимо от их культуры происхождения.
Noticeably missing from the translated text are all the characters-hieroglyphs and the ꜜ character in [oɾiꜜɡami].
The same goes for emoticons and all other rarely seen characters.
This problem affects all available models. And unfortunately the replace_unknowns function does not solve the problem.
Eventually there seems to be a solution to this problem - it is to train Sentencepiece model for new models with byte_fallback option.
This solution was suggested to me by the following topics:
I have trained a new EN_RU model with Sentencepiece with the byte_fallback option.
But with current text detokenization the translation looks like this:
Оригами (<0xE6><0xBB><0x8D>り<0xE5><0xAE><0x8D>, яп. произношение: [oɾi<0xC5><0xB0>ami] или [oɾi<0xE2><0x80><0x8D>ʃami], от ori, означающего «сворачивание», и kami, означающего «бумага» (kami меняется на gami из-за rendaku)) — японское искусство складывания бумаги. В современном использовании слово “оригами” часто используется в качестве всеобъемлющего термина для всех видов практики складывания, независимо от их культуры происхождения.
To correct this I opened a PR:
With the new model trained and the PR data, the translation now looks correct:
Оригами (折り紙, японское произношение: [oɾiɡami] или [oɾiꜜɡami], от ori, означающего «складывание», и kami, означающего «бумага» (kami изменяется на gami из-за рэндаку)) — японское искусство складывания бумаги. В современном употреблении слово “оригами” часто используется как всеобъемлющий термин для всех видов практики складывания, независимо от их культуры происхождения.
Older models with this PR seem to still work correctly.
The only nuance is probably that new models with byte_fallback will produce characters like <0xC5><0xB0> instead of <unk> on Argostranslate versions without PR.
Here is the EN_RU demo model I experimented with
BLEU - 33.60
COMET-22 - 0.8973
valid/ppl - 8.6
Params - 457M