Perhaps this will help, I attach here a model weight calculator where I wrote and marked for myself the most interesting model options (base model highlighted in dark green).
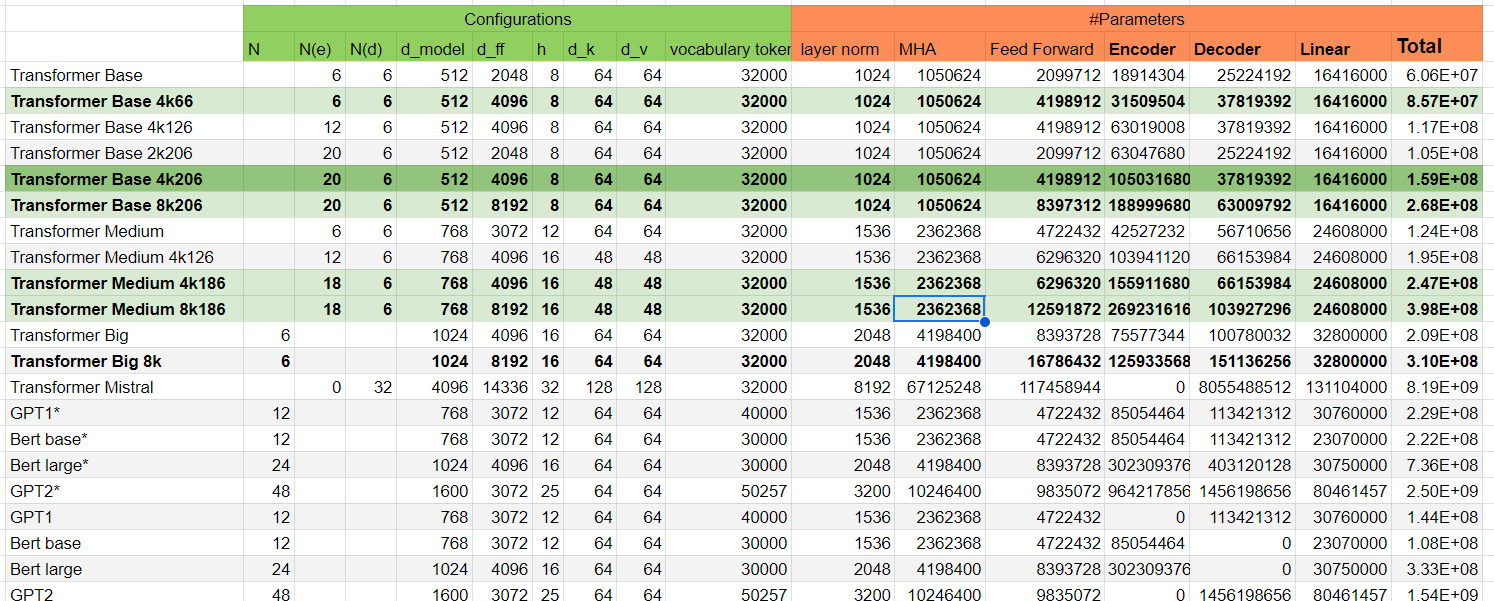
transformer based model parameters calculator
A little later as I can, I’ll post the rationale for this selection of parameters, it’s more of a compilation of my findings from reading the preprints.