That’s awesome! Thanks for sharing these.
2 Likes
Awesome! Thanks for this contribution
I just uploaded this model to argospm-index. It should be live now for new LibreTranslate installations.
Also available for download here:
3 Likes
@lynxpda. Those models you contributed are really awesome!
Also, I used a custom evaluation method measuring the input value of your models to a professional translator who would edit translated texts before official publication : the improvement is in the +20% bracket for RU-EN, and +10% for EN-RU, a lot more than the BLEU scores suggest indeed.
With your permission, I am looking forward to use the research you published to try to improve the German<->English models.
Then, when reading the blueprints, I noticed that some translations actually went worse off : for instance, “экономики с полной занятостью” translates as “full-time economy” instead of “economy with full employment” as was previously -and correctly- the case.
@pierotofy @argosopentech
Do you have any idea how to fine-tune the models so as to correct these hallucinations?
Although there is a “suggestions” option in LibreTranslate, I have not found how to use the suggestions.db once it exists.
2 Likes
@NicoLe First of all, I would like to say thank you very much for your appreciation of the quality of the models.
Due to the peculiarities of NMT it is very difficult to completely exclude translation inaccuracies:
- The translation is rather statistical in nature:
- Most likely, the old model was trained on data containing a large share of the desired domain (economy, politics)
- The new model was trained on a much larger amount of data from different domains (about 150M sentence pairs in total).
- even Google and Deepl translators offer the possibility to adapt the translator to a specific domain, such as:
AutoML Translation beginner’s guide
The Translation API covers a huge number of language pairs and does a great job with general-purpose text. Where AutoML Translation really shines is for the “last mile” between generic translation tasks and specific, niche vocabularies. Our custom models start from the generic Translation API model, but add a layer that specifically helps the model get the right translation for domain-specific content that matters to you.
- Translation is very context dependent and for example document level NMT models will more often show a more coherent translation than sentence level models, as in our case.
In my case, the goal was to get a model that would, on average, produce acceptable results on most domains, while maximizing Quality/Size.
In reality, we have to try to find a compromise, since quality does not improve linearly with size and trying to avoid bias in training data from any domain/area.
If you want to customize the models for yourself, I am happy to share control points and training configuration files.
You can continue training by adding your own data (be careful here, you need to avoid the effect of catastrophic forgetting, I can share the corpus itself, but the total size is about 20Gb).
You can also try to train the Lora network and merge the resulting model with the main model (as far as I know, OpenNMT-py supports this functionality, but I haven’t had a chance to use it yet).
P.S. For my purposes of translating scientific and technical documentation, I have so far decided to go the following way: I collected a profile corpus of text for 42M sentences and formed a synthetic corpus using back translation to train a very large model (more than 400M parameters)).
I hope as a result to strongly outperform DeepL in translation quality (yep, ambitious), at least in this particular area, for professional purposes I think it is justified, but not for fast general translation models.
2 Likes
Perhaps this will help, I attach here a model weight calculator where I wrote and marked for myself the most interesting model options (base model highlighted in dark green).
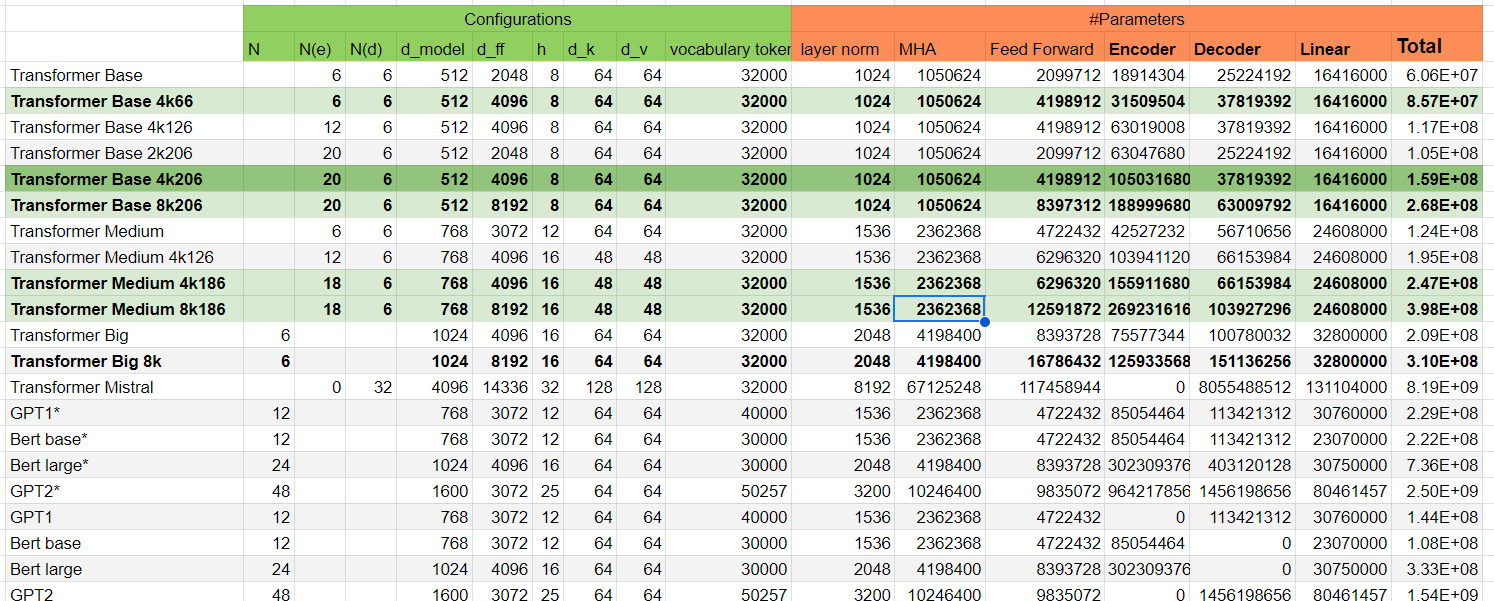
transformer based model parameters calculator
A little later as I can, I’ll post the rationale for this selection of parameters, it’s more of a compilation of my findings from reading the preprints.
1 Like
Well, the little quirk I wrote about notwithstanding, it’s mission accomplished for your en-ru models and ru-en too.
I will first try to understand your proceedings, as I am not so familiar with data science.
1 Like
Speaking of weirdness, I think I have a clue what it might be related to and how to fix it (train it from scratch).
In the data I used a fairly large percentage of extracted CCMatrix bitexts and synthetic back-translation corpora.
I recently came across research where such text corpora are suggested to be labeled with a special token, e.g. src_prefix = <BT>
This should help to separate the data during training and make it clear to the model where the real texts are and where the synthetic ones are.
I have slightly modified Locomotive/train.py and am trying to train a Kabylian language model now, I can say that it works and allows to use the transfer learning method and train multi-language models.
Here are the links to the preprints that guided me:
1 Like
Could you please send once again the script archive you mentioned on Dec26 in the issue?
I’m attaching the archive again. As is.
In general, almost all functionality is already implemented in Lokomotiv.
If you have any additional questions, you can also write in a private message, I will try to answer.
1 Like