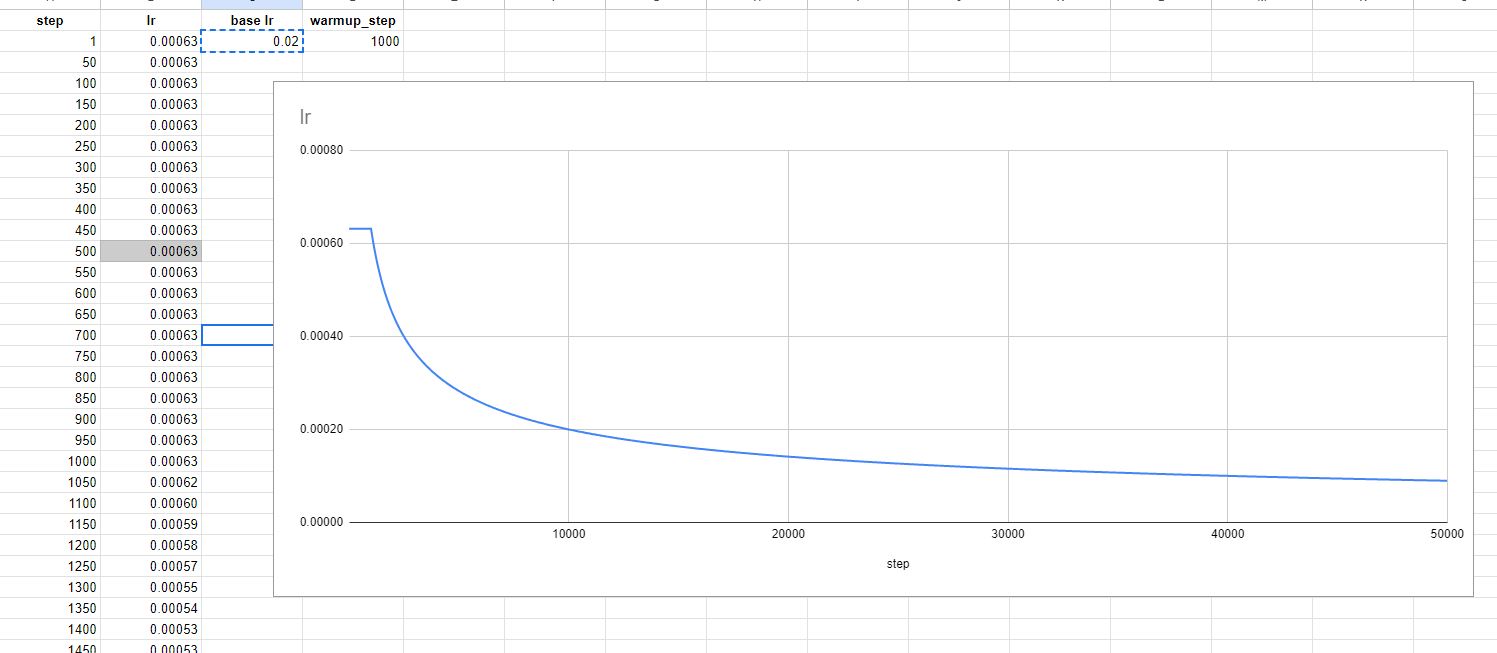
I still use default (rsqrt with 16k warming steps), which may not be optimal.
However, the vanishing gradients appear after the warming period, so they would appear anyway with another scheduler I guess.
I will look for the method to assemble bytes into tokens and keep you posted.
If you use these values and the default planner, you will likely never get a good enough model, unless of course you are training for more than 500,000 steps. A high LR allows you to train models quickly, a low LR allows you to achieve accuracy, with the default values even at 100,000 steps the LR value will be too high to “polish the model”.
Over the course of your training, the LR value should drop to between 0.0001 and 0.00005. Also to train a model from scratch you need a warm-up with increasing LR, otherwise there is a risk of model divergence at the beginning of training.
Thanks for the tip. I changed the decode method with only this line : return tokenizer.lazy_processor().decode_pieces(tokens)
and it works.
Modified it also in the eval.py script, evaluation score on flores200 are unchanged, so it is twice reassuring (first, because the method produces the .evl translation, and second, because you would not expect an evaluation dataset to contain OOV terms).
About the LR, I never thought about it, but it probably explains why I could not train “big” models.
Then, with the effective batch size at 200k and 32k steps (more or less two days of training for a 150M model), most of the time I reach these values - training accuracy ~77 - training ppl ~ 10 - validation accuracy ~ 80 - validation ppl ~ 8, depending on other parameters in the config, so I have not been giving much atention to the issue.
I take a look at the scheduler you sents a while ago to see what it would give with noam decay.
Judging by the parameters you stop at LR=0.00084, which is still quite high.
You can try to continue training an already trained model (by setting “reset_optim”: “all”) with the following parameters:
That said, you should notice a further improvement in the model by ppl. If LR is high or does not change for a long time, the model training reaches a plateau early and stops improving.
Thanks for the idea, with high LR, the training gets to much bias, validation BLEU starts oscillating after a while and I’ve often come to synthetize better models from earlier checkpoints with the “inflight” option.
I am training models towards de, with a BT set, at the moment, I’ll polish them with your schedule afterwards.
Also thanks for the parameters with the Geglu function and 3072 transformer ff. I trained several prototypes around them, and although gated-activation models are as good as those with 4096ff, the vanilla model with ‘relu’ was quite bad : I would have dropped this ff value earlier in my work had you not said it was your best.