Summary
So far, I have trained my own model twice, but both attempts yielded poor results. I am seeking advice on best practices for configuring parameters such as the learning rate, warmup steps, and others, as well as understanding how these parameters function.
First Attempt
During my first attempt, I set the learning rate to 0.005, with a total of 100,000 steps and approximately 16,000 warmup steps.
I discovered that changes to
warmup_stepsinconfig.jsondo not take effect if you resume training from a checkpoint after making the change, unless you start training from scratch. Therefore, in the first attempt, I believe there was virtually no warmup in practice.
The batch size was 3,072, but I don’t think it significantly impacted the long training process.
Ultimately, the model performed poorly. It was learning, but at a very slow pace. Specifically, the training accuracy reached only 18.5 after 100,000 steps.
The learning rate progressively decreased, ending around 5e-4.
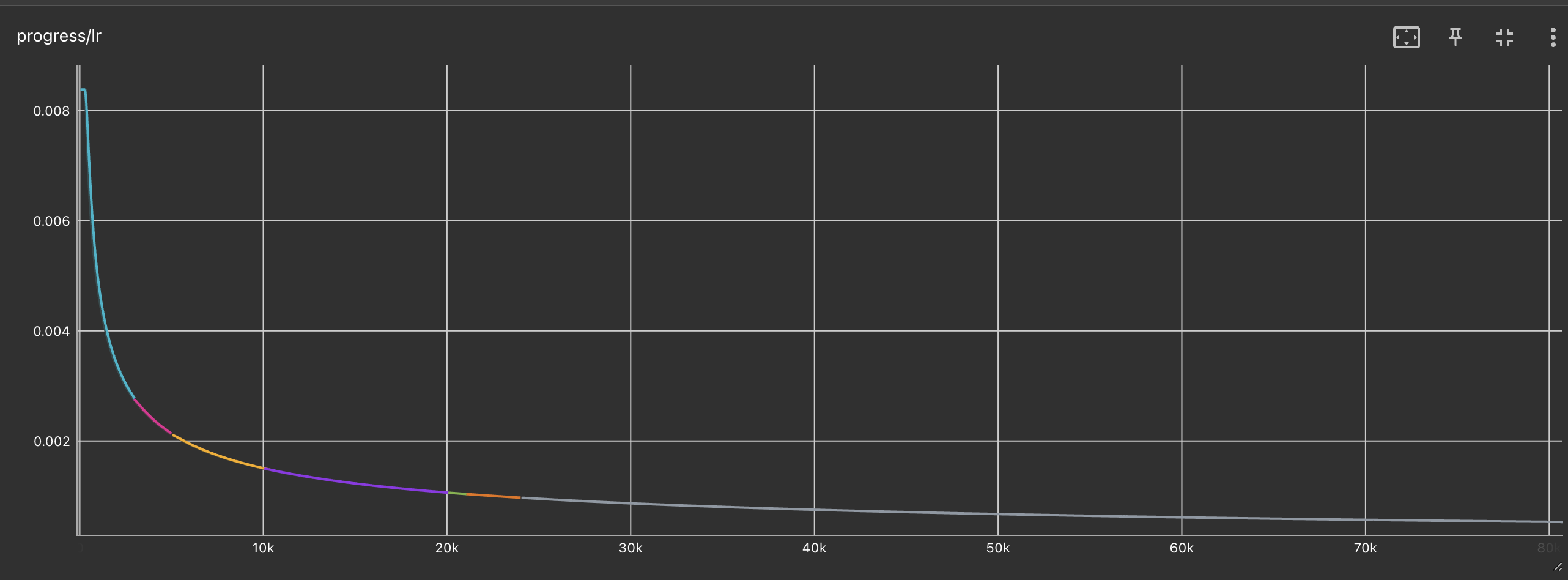
The validation BLEU score was only 0.08, and I would also like to know if the BLEU score is valued between [0,1] or [0,100].
There are several other metrics, and I will list their final values here, which may be helpful. Generally, they improved over the 100,000 training steps (either higher or lower is better), but the improvement was quite slow.
- train/ppl: 751.6
- train/tgtper: 1.06e+4
- train/xent: 6.622
- valid/acc: 20.5
- valid/tgtper: 359.8
- valid/ppl: 564.1
- valid/xent: 6.331
Second Attempt
After reflecting on the first attempt, I suspected that the learning rate was too low. Thus, I configured the parameters as follows:
(Irrelevant configurations, such as datasets, have been omitted)
{
"vocab_size": 80000,
"batch_size": 3072,
"train_steps": 20000,
"valid_steps": 500,
"save_checkpoint_steps": 1000,
"warmup_steps": 1400,
"valid_batch_size": 3072,
"learning_rate": 0.17,
"max_grad_norm": 1.0,
"accum_count": 12,
"num_worker": 6,
"model_dtype": "fp32",
"keep_checkpoint": 12,
"early_stopping": 5
}
However, the learning rate did not schedule as expected.
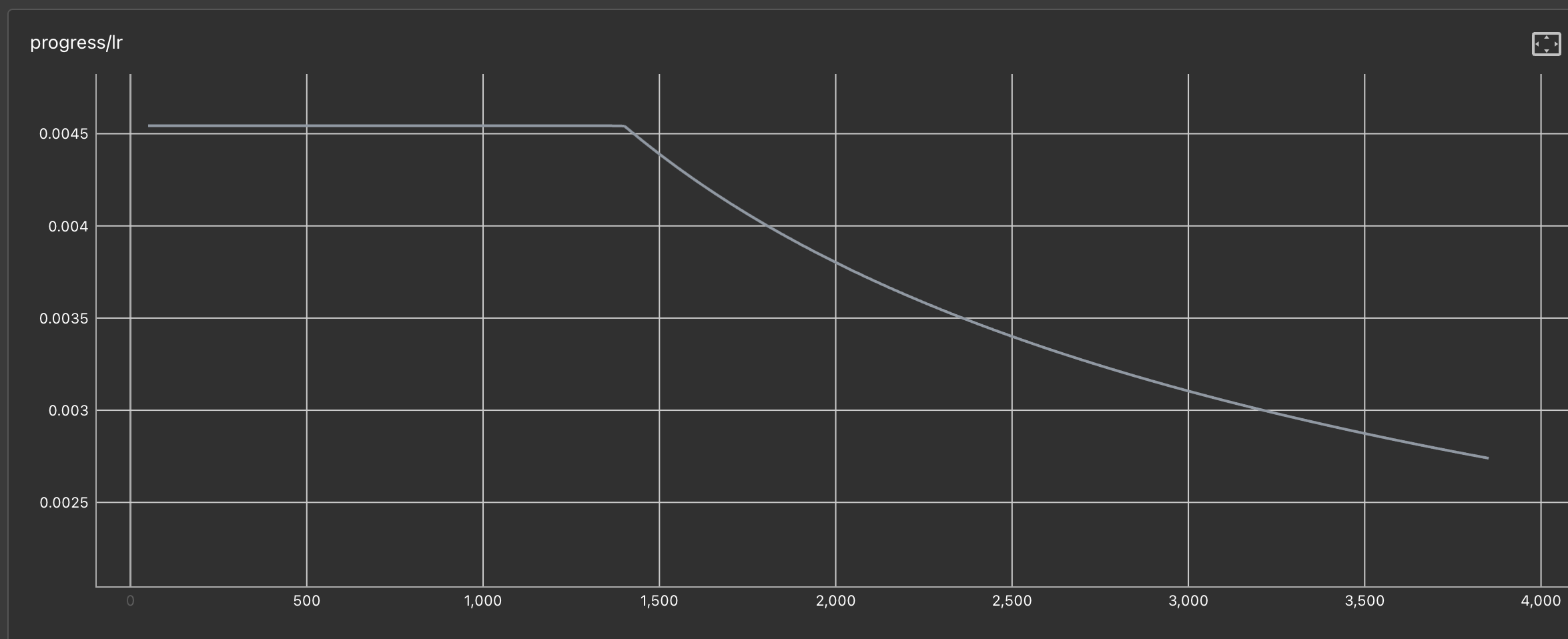
As I understand it, based on this configuration, the learning rate should start from a small value and linearly increase to the target learning rate (0.17 in my case).
Instead, the learning rate remained fixed at 0.004543 during the warmup steps and only decreased after the warmup period.
The learning process was indeed faster than the first attempt, but I still believe this configuration is not optimal.
I would like to know what the common values for these parameters are. By default, the learning rate remains lower than the target learning rate during warmup and never reaches or tends to get close to the target learning rate. Is this behavior normal?