Regarding the relationship between encoder and decoder depths, it is well described here:
Models with an asymmetrical number of layers work well, but I needed the deepest possible decoder to obtain maximum output quality.
I follow the following strategy:
The quality is most affected by the depth of the encoder and then the decoder.
The number of layers should not exceed 20 (there are studies that suggest that higher magnification may even worsen the quality)
The number of decoder layers most affects the speed of inference.
The general rule is that with the total number of goals, productivity will be approximately the same, all other things being equal. For example, a model with a total of 30 layers and 8 heads per layer (d_model = 512) = 240 heads in total = 15 layers and 16 heads per layer (d_model = 1024) = 240 heads in total
I’ll sum it up my way :
This paper suggests that training will collapse for a decoder deeper than 12 layers on basic transformers, so the researchers used two regularisation methods (cross-attention drop and collapse reducing training) to get over it and obtain quite similar effects to those of super-deep encoders/vanilla decoder models.
Said effects are assessed with BLEU, which volatility is discussed hitherto in another part of this forum, so maybe better is an artefact due to bias regarding the evaluation dataset, innit?
How can you even manage to implement such features in Locomotive? Did you modify onmt-train? There’s nothing like activation function or ROPE in the config.yml file used for training (and YES I am reaaaally interested! even skipped lunch.).
I needed the deepest possible decoder to obtain maximum output quality.
I do not know exactly how you proceed, but I only change one hyperparameter at a time, and always try at least 3 values, than compare using several methods (know this isn’t MLOps-wise…) analyze the results with caution.
Language is by nature a geometrically non-descript artefact. Representing it with a discrete number of tokens and training it on the equivalent of a nation’s coffee-break chitchat (if you consider anyone will utter about a thousand sentences a day, multiply by the population, and add the thing as a denominator to your dataset) through an pretty regular mathematical construct is never going to be straightforward, even if the coffee break’s discussion is prize-winning. BLEU evaluation is simplistic -though ubiquitous, people love simplistic- and I welcome the COMET.
I have almost always noticed n-th degree effects so I became careful, sometimes the parameter you think is doing the job only potentializes another one. Sometimes, the improvement shows on one metric, not the others…
And I notice this in particular for encoding/decoding layers and label_smoothing (think about it, you might even overcome the Google).
In fact, you can skip the moment of burying the deep decoder. Their instability was due to the difference in transformer architectures (location of pre-norm or post-norm normalization). Now in OpenNMT-py this has been corrected and it is possible to train models with a deep decoder.
Regarding RoPE and GeGLU - Locomotive has the OpenNMT-py framework under the hood and virtually all training goes through it, and Locomotive is actually a script for automating the creation of a training configuration for OpenNMT-py.
And now OpenNMT-py supports RoPE and GeGLU and much more. Accordingly, I added train.py so that the configuration file is generated correctly.
There was another problem with subsequent conversion via Ctranslate2 to a model for ArgosTranslate.
I also had to fix even OpenNMT-py itself to be able to train models with up to 500M parameters with large batch sizes (yes, there is an error in the framework when saving the model to disk during training).
When I have time, I will open a PR for these changes; quite a lot of them have accumulated.
Regarding RoPE and GeGLU - these are advanced developments used, including in Llama 3 and Mixtral and many other LLMs.
As I said (edited my post), I do not doubt quality as a whole, only, I am cautious after several seemingly inconsistent results on another language pair.
So you edited train.py in order for the config.yml to include such parameters as activation function and normalisation params, a.s.o… did you add a logger as well? I am into thinking of a simple one that would log all of what goes to screen for restrospective parsing (tensorboard is only as good as training hasn’t stopped).
no, I didn’t add a registrar. I just copied the logs into a folder. I see no reason why not run tensorboard separately from training to open logs from a folder.
In fact, only this part from train.py is enough. You can simply put it in a separate script to open logs of previously trained models:
if args.tensorboard:
print("Launching tensorboard")
from tensorboard import program
import webbrowser
import mimetypes
log_dir = os.path.join(onmt_dir, "logs")
# Allow tensorboard to run on Windows due to mimetypes bug: https://github.com/microsoft/vscode-python/pull/16203
mimetypes.add_type("application/javascript", ".js")
tb = program.TensorBoard()
tb.configure(argv=[None, '--logdir', os.path.abspath(log_dir)])
url = tb.launch()
print(f"Tensorboard URL: {url}")
webbrowser.open(url)
cmd += ["--tensorboard", "--tensorboard_log_dir", log_dir]
problem with tensorboard logs, they’re code, not values. I would like to be able to get the values using another script retrospectively and foremost, to be able to compare trainings between one another.
I can develop this for a different PR…
Your model does not charges straightforwardly using a “package_to_file.py” script as described in the argos doc. I’ve got the files all splattered across the packages directory; probably a side effect of the bug you mentioned.
So I repacked it manually to “translate-en_ru-1_9” directory, restarted… and it ACES!!!.
A few insignificant mistakes, I would rate it above 96. It is at par with G and D, they too make a few mistakes. Fluidity, well I was not expecting it anymore from a transformer, but it is there.
I didn’t use GELU, but GeGLU (it’s called gated gelu), which is a more complex activation function. but be careful, for example with FF GeGLU 2048 the number of parameters will be equal to = FF GELU/RELU 3072. That is, it’s actually 1.5 times more.
You can read more in this discussion:
Ultimately, I settled on relative positional encoding of embeddings since they ultimately matched the quality of ROPE.
Moreover, judging by the principle of operation of relative positional encoding of embeddings, they should in some cases exceed conventional positional encoding.
Here is an example of my training script (only works with modified train.py) to train a new language to a model previously trained by me with a vocab update
Ok my! Your script modifies so many parameters I have trouble understanding which is what for, so I come again with some more questions, and some comments based on what I figured out
Waiting for PR #1687 to CTranslate2, you used RPE with 20 max relative positions, because although it converges more slowly, it does have the same end-result (that’s in the issue you put as link)
gated-gelu with 6144 ff is only feasible with modifying Locomotive and updating the CTranslate library, so I’ll have to wait for your PR. It’s far more complex than swish or gelu to understand, and it yields results in several preprints
Meanwhile, if I want to try gelu, the equivalent feed-forward should be set to 4096 isn’t it? I know it’ll be underwhelming, but it’ll always be better than relu.
i see you enabled multi-GPU training.
I have trouble understanding all the modifications you made to batch_size, valid_batch_size, accum_count and the bizarre (not a multiple of 1024) bucket_size. Is that new language very low-resource? has it a particular tokenization? Did you have memory issues? or is it to optimise multi-GPU train?
pagedadamw8 with high learning rate and noam decay I definitely understand, adamw and noam decay allow a stable, fast convergence with a high learning rate while paging saves memory.
As for the very small warmup, did you shorten it by a square factor of your LR’s multiplicator? has the model read enough data before you enter decay curve, or it does not matter? I thought data had to be fully read at least once within the warmup period.
you average the 3 last checkpoints in the end and set early_stopping to 0, is it a feature of fast learning?
the “reset_optim” option is defined, but OpenNMT doc mentions it is to be used with “train_from” : what do you use it for?
“src_seq_length” & “tgt_seq_length” are filtering input over said number of tokens. Is the 185 value specific to your language or dataset? If not, what made you specify it?
I saw what you engineered here is brilliant, it’s a best of many preprints and the way your last model translates is here as proof. But I cannot reproduce it without being able to explain the choices, and they are so radical I hope you won’t mind walking me through them.
Uh! so many questions, I’ll try to answer them if possible:
Yes, everything is correct, I confirm! RPE vs ROPE on sequences less than 512 has only one drawback, RPE is slightly slower. But in any case it is better than PE.
To use gated-gelu in Locomotiv, just add the necessary parameters here
And after that you can quite successfully complete your studies. Problems can only be with conversion, but they can also be solved on the spot in just a couple of minutes for Ctranslate2 (and the finished model will work with any version)
everything is correct in terms of the number of parameters GELU = RELU. Quality may increase slightly. Unfortunately, I don’t have exact data on how much this will affect the quality.
“bucket_size” is just the size of the basket where training sentences are added, where they change on the fly and are shuffled. Effective bucket size = “bucket_size” * “num_workers” and this choice was due to unstable operation on my hardware in a configuration with two GPUs, it does not affect the quality in any way and if it works for you by default, you don’t have to change anything)
In addition to the fact that the page optimizer saves memory in edge cases, pagedadamw8 is also an 8-bit optimizer, which allows you to save even more memory and use large batch sizes, which affects speed and quality
Regarding the small warm-up… This was a model I had already pre-trained, for which I simply updated the dictionary for another language and started training not from scratch, which allowed me to save a lot of resources. I described this in the next topic.
I just turned off the early stop so it wouldn’t interfere. the number of averaged control points is just a field for quick experiments
as I wrote above, resetting the optimizer states is needed to train the pre-trained model. The algorithm is simple:
For example, you start training the EN_DE model but stop at any time before saving the first control point. Then you throw into the folder with checkpoints, for example, a previously trained model openmt.model_step_100000.pt with absolutely the same architecture, but for a different language pair, for example FR_DE, and reset the optimizer state and update vocab - “reset_optim”: “all”, “update_vocab”: “True”.
OpenNMT-py will compare all available tokens between models, and initialize missing ones as usual.
after that, set the LR scheduler to a non-standard value with a short warm-up (500-1000) and select the curve so that the maximum LR does not exceed, for example, 0.0015, spend the main part between 0.0005 - 0.0002 and at the end of the workout it would drop to 0.0001. For a given number of steps, for example 5000 - 15000 (to taste). You can find a curve, for example, using this table (I made it in a hurry):
Any value from 150 to 300. It’s just that if you come across very long sentences, the memory consumption will be greater. Also, if during inference you come across a sentence longer than you cut off during translation, then the result may be unpredictable (analogous to the length of the LLM context).
Purely empirically selected value.
So there also is an effective bucket size. I noticed earlier that when training with effective batch size equal to the bucket size, models become “dumb”, but with 6 num workers, that’s an effective bucket of 288ko so your 135ko batch is around 47% of it.
I noticed also that training big models require specific tuning, and since their translations have been disappointing, I focused how to attain quality otherwise.
I understand the specific learning schedule is for fine-tuning a EN->RU model to low-resource Finno-ugric languages. What your work implies is quite amazing. Finno-ugric grammar and syntax are nothing like English, and vocabulary classes do not closely match… even a different alphabet should not be much trouble.
Then, upon the src_seq_length and tgt_seq_length, … Do you mean long sentences can be inferred consistently by splitting them according to this parameter, and that if it is not set, any sentence longer than what the model has been will be out of context, hence confabulated? I included in the training data some sentences up to 1000 character which accuracy I was sure of… does it help?
I created the pull request for automated COMET-22 evaluation in Locomotive’s eval.py,
Just use the “–comet” option and specifiy “–flores_dataset” option (I noticed that while “dev” is default, “devtest” is generally used in benchmarks), and you get a comet score within the minute (and a BLEU on top, doesn’t hurt).
As of parameter testing, I think we should discuss it in the “playing around with MT” topic and keep this topic about the original issue.
Hello,
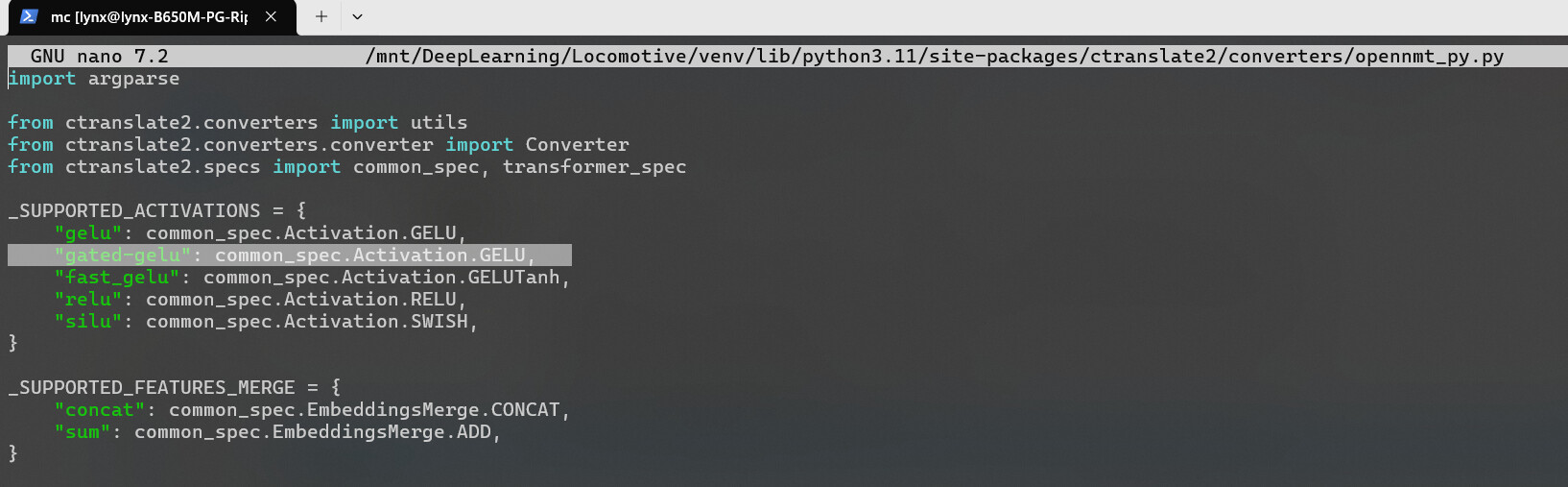
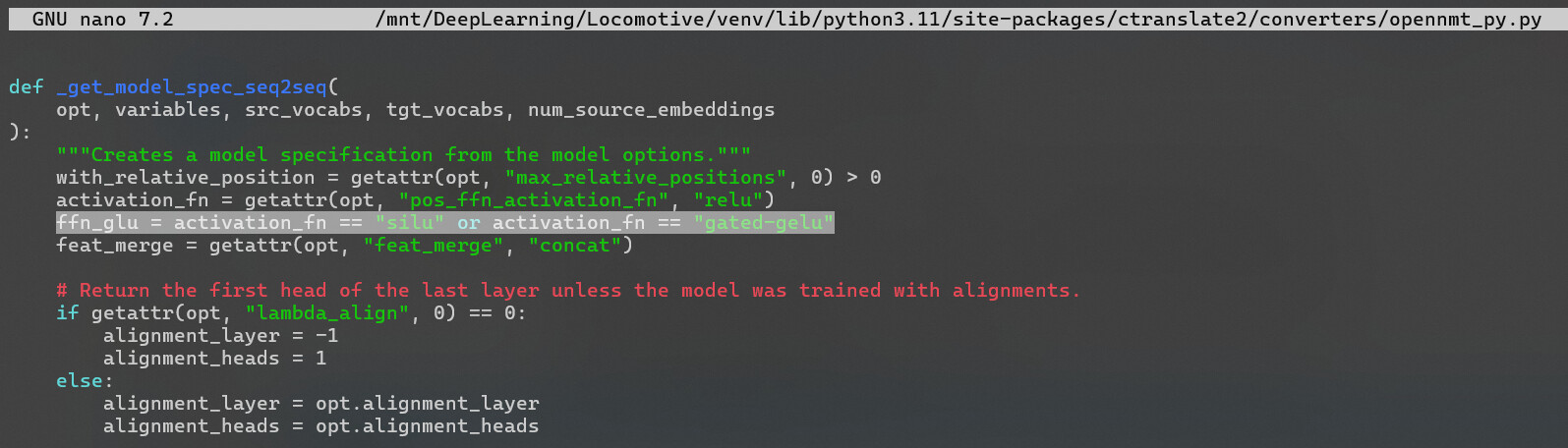
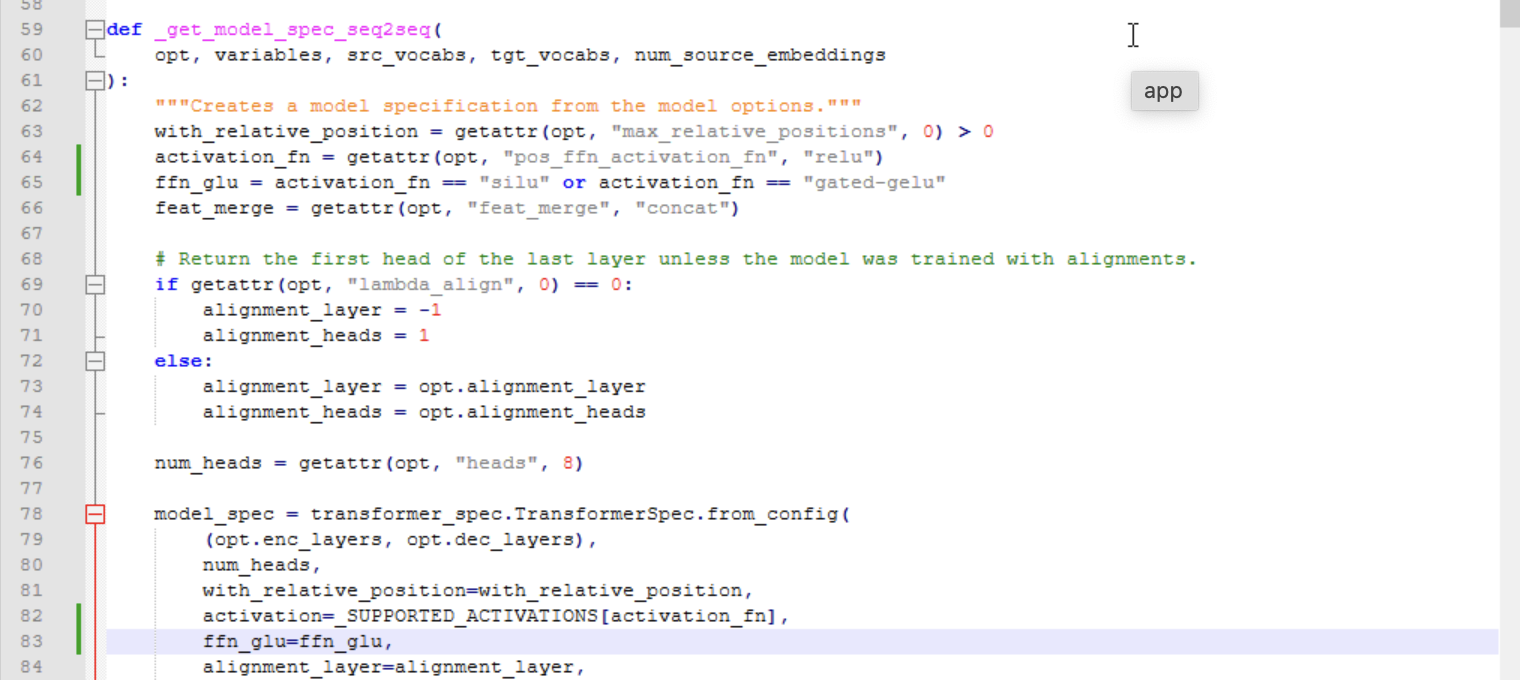
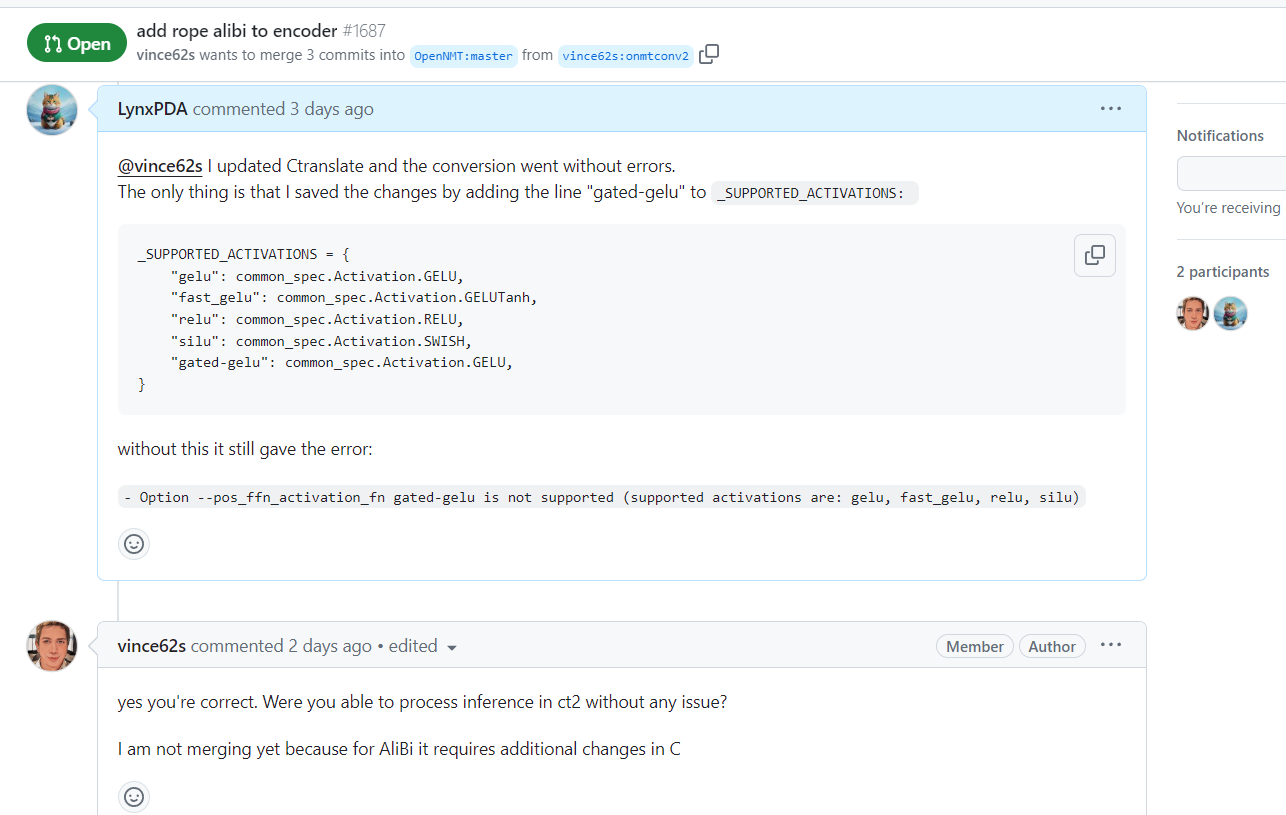
Upon adding the function to the ctranslate2 converter, did you actually implement the ffn_glu variable into the transformer in the vicinity of line 80-82? You specified only two lines to modify, but in PR#1687, those two are different (and, thinking about it, there should be 3).
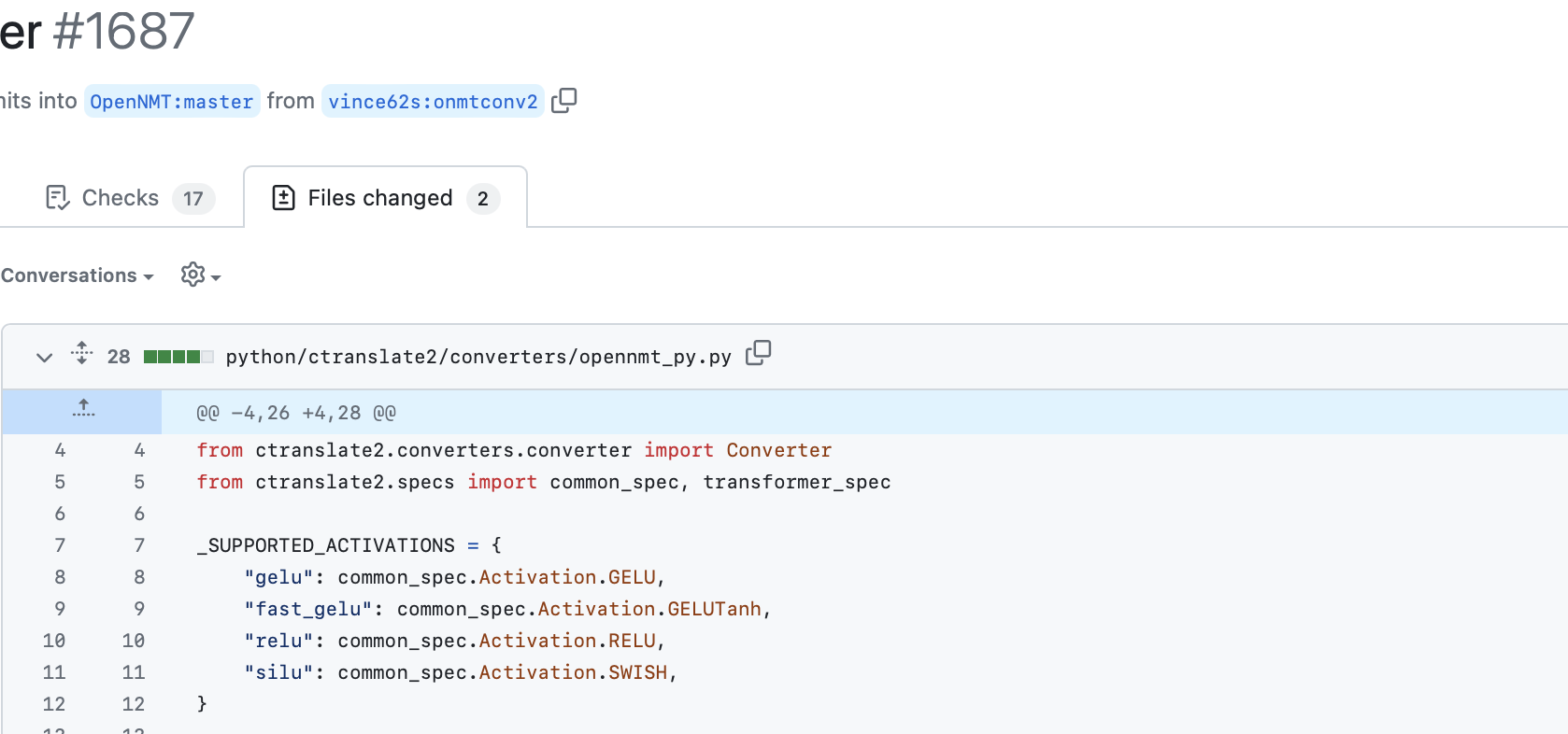
CTranslate2 PR #1687 : at line 8-9, definition of gated-gelu into supported activations is missing. But ffn_glu is defined and valued, then implemented in the transformer’s specs.
After the “silu” finished training, I checked it, both comet & bleu were preposterous so I decided to take a closer look at ctranslate2 implementation of the function. I occurs the version currently used in Locomotive has none… so I went for the PR and noticed those small discrepancies. Sorry, do not have the GitHub token on weekends, so I post here. Coders beware…
Hello, @lynxpda Hope youy didn’t mind me pulling the byte fallback, I needed it for futher operations and I prefer to keep what I run as close to the main branch as possible.
When you trained with RoPE, were you able to produce the model, or did it gave the “numheads” parameter error that you disclosed in CTranslate2 issue #1657, and you switched to RPE then?
Also, I did a non-regression test for absolute position encondig before the last PR and it turned out that sometimes the deep encoder - shallow decoder can fall below the “square” deep model if dropout does not align in the right neurons. That was quite humbIing, but it prompted me to compute COMET scores on every model I had trained so far to double-check, and overall, they show almost no returns (or worse) past the 32k vocab, 25 accum_count, 4k ff, 18 enc/6dec recipe except for those where I introduced RPE and gated activations. So I guess I was not totally fooled after all.
But there might well be recipes that work too for which training did not go in the best direction.
There were no problems with RoPE during training. With OpenNMT-py the model worked completely.
There were problems only with conversion to Ctranslate2, but CTranslate2 PR #1687 solves this problem.