I was writing the pull requests for the translate_flores function and to add an argument to switch to flores devtest instead of dev on demand… and since it was intertwined with COMET score automation, I finished scripting it nonetheless.
Still have to test it thoroughly though : because of the protobuf discrepancy, verification will require installing locomotive with unbabel-comet from scratch so it’ll be a few weeks before coming to you.
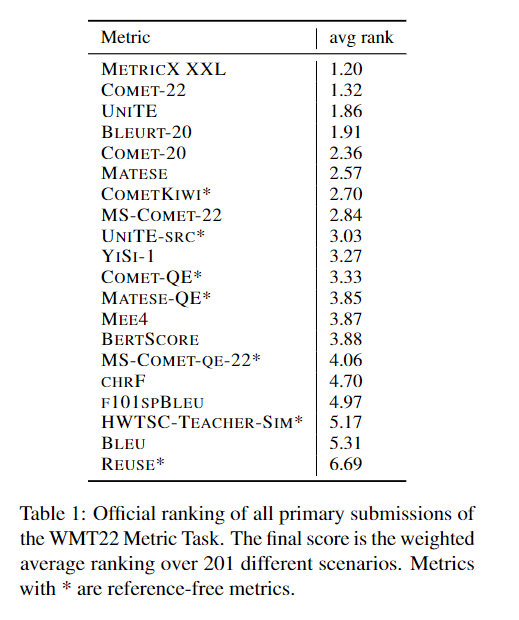
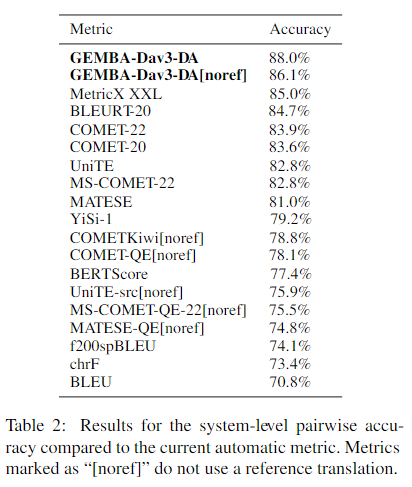
COMET is actually helpful because devoid of the biases that hamper BLEU evaluation, even though it is far less sensitive.
An example :
BLEU-wise, BASE models are indiscernable from models with “accum_count” = 25 and transformer_ff" = 4096.
Upon manual evaluation, scores are somewhat better with the latter : BASE models are unable to translate any term above a certain number of tokens, rendering it as gibberish, whereas the “GRASP” models as I call them translate better, but use a poor syntax and some semantic shortcuts that lowers the BLEU score disproportionately.
Although the score difference is only 1%, COMET is able to highlight better translations quite consitently : one has to be aware that 1% more in COMET is actually worth a big deal for final users.
Actually, I use now both metrics : when BLEU shots up on either the dev or devtest flores it also means something : the best german->English model I have trained so far has a BLEU(dev) of 69, way above the others, and actually gives better translations, even though the COMET score is quite similar.
I’ll tell you how I came by it when I’m finished dwelling into hyperparameters for good. I already came into quite interesting conclusions that you might like to read.
For now, I established that,
- optimal “transformer_ff” value is 8*word_vec_size (or hidden_size, the two must be equal)
- optimal “enc_layers” values are multiples of “dec_layers”… which means 18 enc is better than 20 if you leave the decoder as default. Actually 12 layers is not bad either, depending on the quality of your training dataset it can be even better than 20…
- there is a second degree effect between “vocab_size” and “enc_layers” : the more layers, the blurrier the classes, therefore at default (6) encoding layers value, optimal “vocab_size” is 50k, but not for 12 or 18 layers (have used 32k, testing 40k)
- the more layers, the blurrier the classes, so I have dabbled with a known antidote : “label_smoothing” After fumbling quite a few times, I found 0.125 to improve marginally the synonym issue on an 18 layers model
- also noticed that models synthetized in retrospect with the “inflight” argument from one of the two checkpoints having the highest “val.BLEU” value are often better than end-of-training ones…
Of course, all of this is highly dependent on the quality of your training data, which is 80% of your model’s ability indeed. But the last 20% helps beating many of the publicly available systems (except Google for exactitude and DeepL for fluidity).
Google’s job is data so there is no way they won’t always have the best aligned sources to train their models, hence be in front regarding semantic exactitude
With DeepL, an OpenNMT model can actually score at par word-to-word-wise. Their advantage lies in fluidity. How do they obtain such verismilitude in translation is anyone’s guess, mine being that are likely to use Levenshtein-like decoders, probably in combination with some conformer features.
What I came to take as a certainty is that usual transformers simply are unable of such fluidity. It takes in-depth architecture modification to recognize and rearrange not only individual tokens but also process them within syntagmic blocks of tokens probably defined as a class. I’m not even sure the attention mechanism is apt at this kind of task, it looks more like a convolutional mechanism or placeholder susbtitution being at work, hence my guess.