Link to paper: https://arxiv.org/pdf/2210.11621.pdf
Side question: are there benchmarks of the BLEU scores for current argos models?
I don’t think so but I was thinking about it. it would be necessary to benchmark all argos models to be able to compare with other models.
I have tried to export the model to ctranslate2 but I can’t manage with the tokenizer.
I also didn’t manage to use it with argos, it looks like you have to use their script to tokenize
I have tried:
# wget https://huggingface.co/alirezamsh/small100/raw/main/tokenization_small100.py
# ct2-transformers-converter --model alirezamsh/small100 --output_dir model
from tokenization_small100 import SMALL100Tokenizer
import ctranslate2
translator = ctranslate2.Translator("model")
tokenizer = SMALL100Tokenizer.from_pretrained("alirezamsh/small100")
tokenizer.src_lang = "en"
source = tokenizer.convert_ids_to_tokens(tokenizer.encode("Hello world, it's a small test"))
target_prefix = [tokenizer.lang_code_to_token["fr"]]
results = translator.translate_batch([source], target_prefix=[target_prefix])
target = results[0].hypotheses[0][1:]
print(tokenizer.decode(tokenizer.convert_tokens_to_ids(target)))
but the model return “ku на, it’s a small test” xD
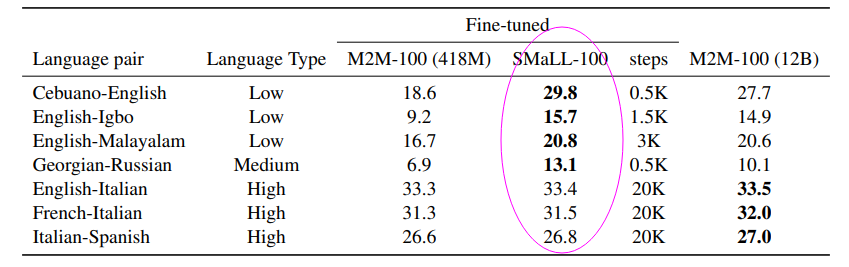
Here are some links for BLEU scores:
In general I think it can be difficult to compare scores unless your both using the same test andl language. We could try comparing Argos Translate Sacrebleu scores to other models for languages Sacrebleu supports.
yes, it can also be interesting to compare an old to a new model.
it may be a problem with ctranslate2 or a bad use of the model.
but if already with ctranslate2 it doesn’t work it won’t work with argos
I didn’t look any further but I couldn’t get it to work either just by replacing the m2m model, there must be some other adjustment to make.
it would be good to succeed in making it work because if it offers the same results as m2m but being 3x smaller and 4x faster, it’s super interesting.
Interesting, good to see it works. I don’t think this would be a good candidate for including in Argos Translate. I’m planning to stick with the SentencePiece tokenizer and don’t want to include a bunch of custom tokenizers. I think SentencePiece is the most popular tokenization library so there will probably be plenty of models coming out that support it. I’m also looking into training my own custom Argos Translate multilingual models too where compatibility wouldn’t be an issue.