Hello everyone,
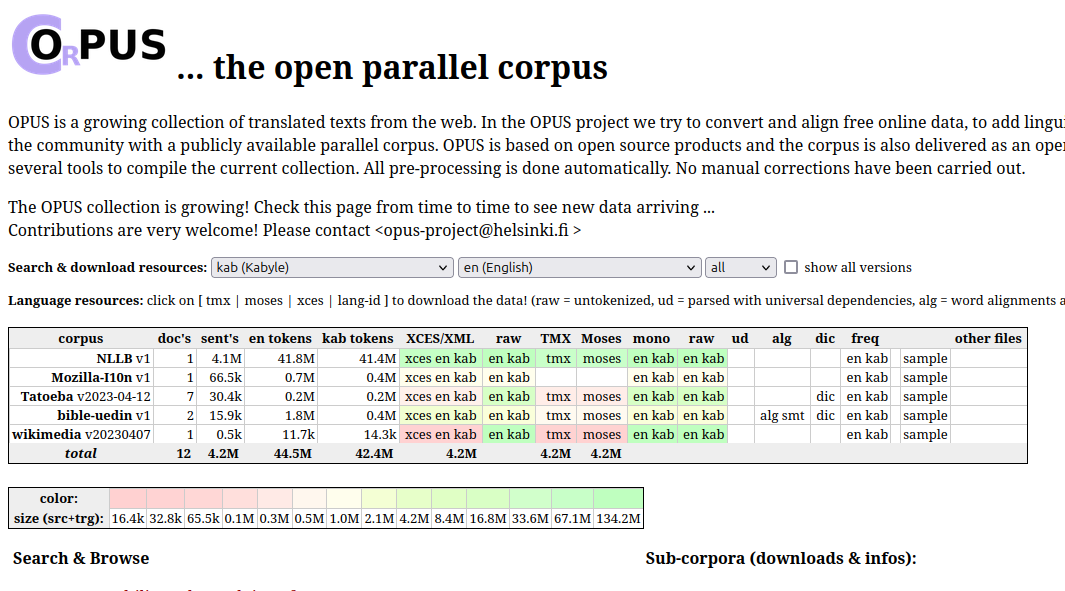
I tried to generate a Kabyle language model for Argos Translate and LibreTranslate using Locomotive and opus://Tatoeba but I failed.
Kabyle language is well ressourced on Tatoeba and our community is contributing over there.
Link : Number of sentences per language - Tatoeba
For now, there is no quiet good service on the Web offering a usable translation. I tried NLLB-200 for kabyle language but it is far from generating usable translation from English or French to Kabyle, such as MinT implemented by Wikipedia.
Someone made a website to offer kabyle translation but the licence is not clear even if the data and corpus came from Tatoeba.
Link : Tasuqilt
Translations from that website are okay and usable. This is why I’m looking for the help of our LibreTranslate community to generate even an beta model for kabyle language to test it.
Tomorrow, January 12th, we berber people across northen Africa are celebrating our new year called : Yennayer. So happy new year everyone ![]() and best wishes.
and best wishes.
Have a nice day.