At times, LibreTranslate fails at its mission in curious ways, and among them is when it returns English words as translations that are not, in fact, English words at all.
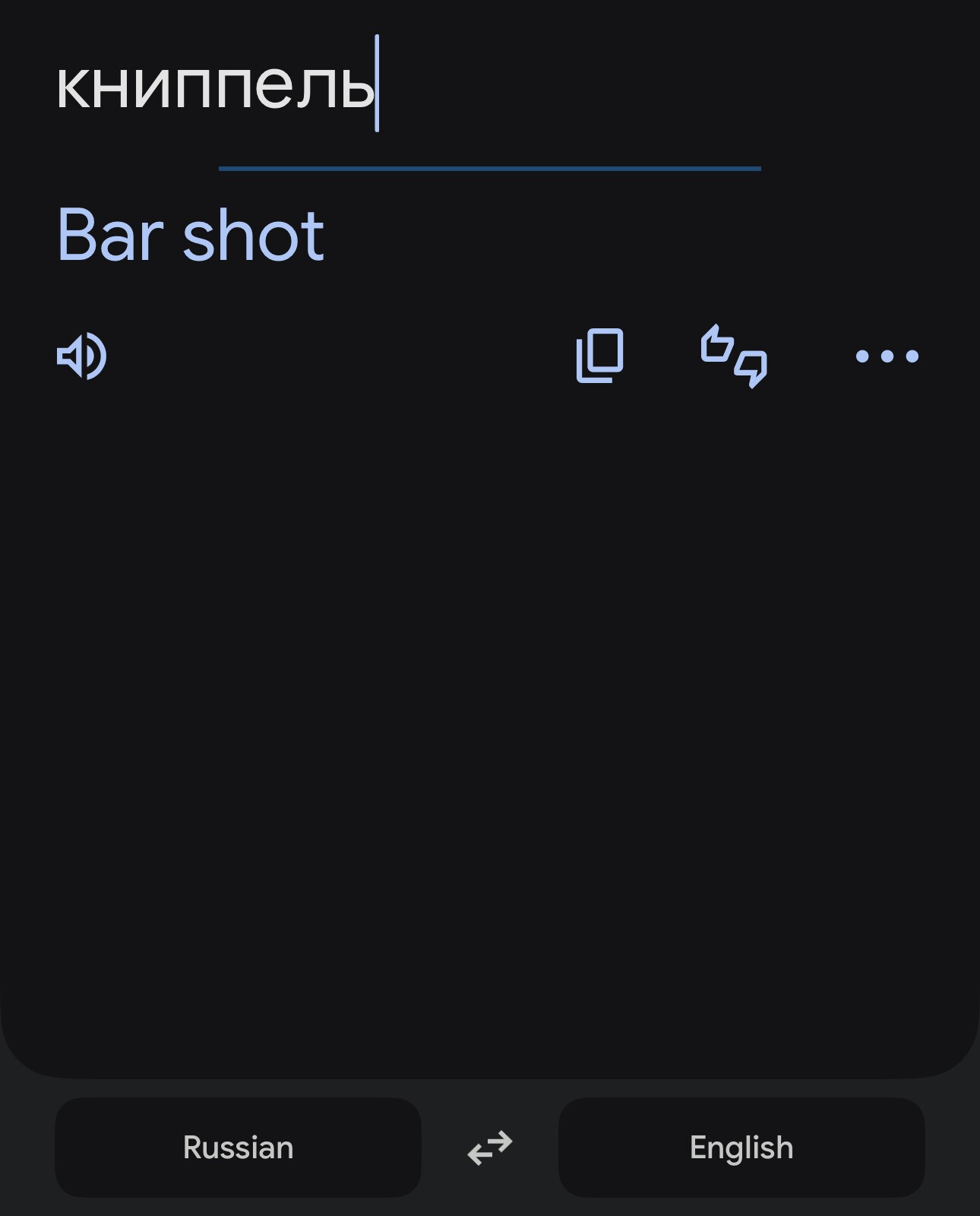
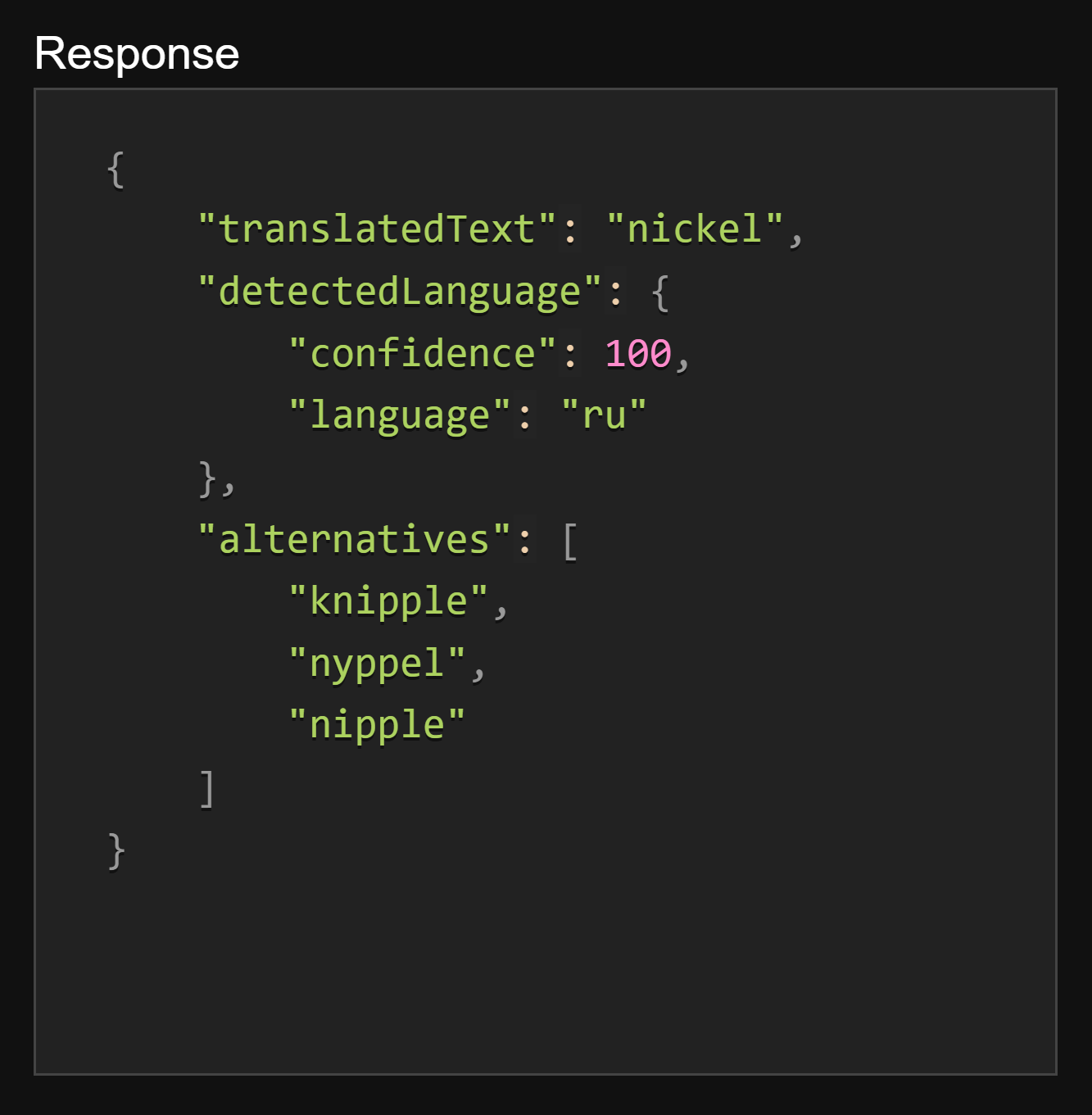
One example of this (for brevity) is the Russian word “книппель”, which the Google Translate Mobile App correctly translates as “bar shot” (i.e., such as would be fired from a cannon):
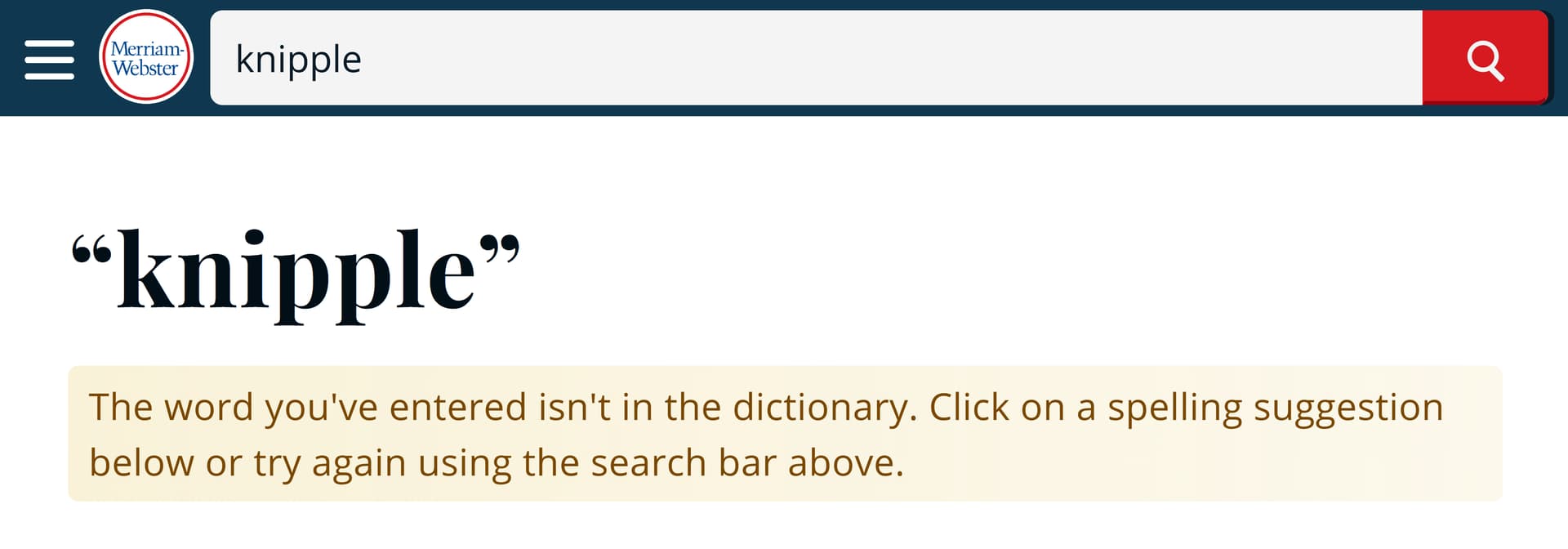
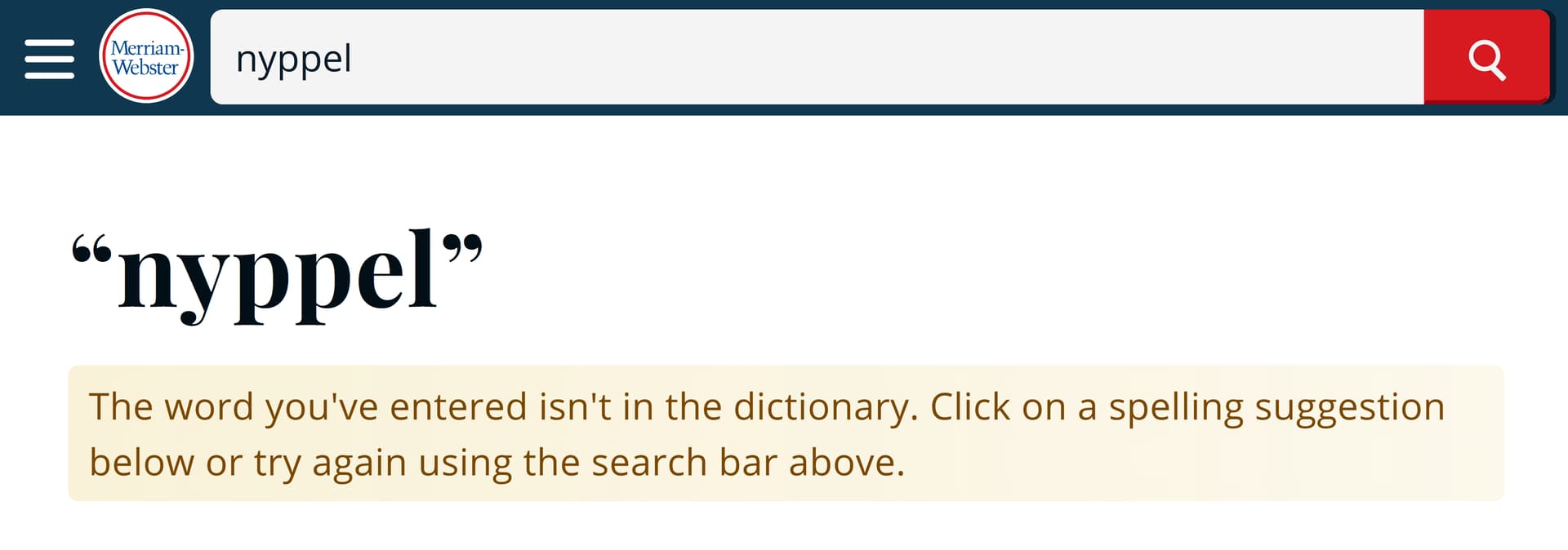
The mistranslation aside, of salient note are the alternatives that are returned above. Two out of the three “English” words LibreTranslate is suggesting as alternate translations (“nyppel” and “knipple”) are not, in fact, English words at all:
For single word detection, there’s probably some incorrect data in LexiLang/dictionaries at main · LibreTranslate/LexiLang · GitHub. You can help improve the result by reviewing the dictionary for the wrong language detected (in the “nickel” case, see if Russian has some incorrect data in it).
So there is no way to ensure that words returned from the API as translations or alternatives are actual dictionary words? Is it not possible for the maintainers to run a comparison of the word lists in each language model against each language’s official dictionary, so they can clear out all of the words in them that aren’t real?
It’s difficult because vocabularies are not exhaustive and some words are perfectly valid in multiple languages. So as a general solution, probably not.
But if your translation space is limited / predictable you could add that logic as a post-translation step.
The problem here is not so much that there are words being used that have different meanings in other languages, but rather that words are being provided back as translations to English that do not exist at all, with ANY meaning, in the English language.
For them to be provided, they had to exist in the model as “English” words – but since they are not English words, and do not appear in the English dictionary, wouldn’t it make sense to remove or remap these improper tokens from the tokenizer and retrain the model? I.e, rebuild the English tokenizer (SentencePiece/BPE) from a curated English corpus that only contains English Dictionary words, then retrain or fine‑tune the Argos/OpenNMT model using that tokenizer?
This would remove any words not in the English Dictionary from being able to be used as either primary translations or “alternative” English words.