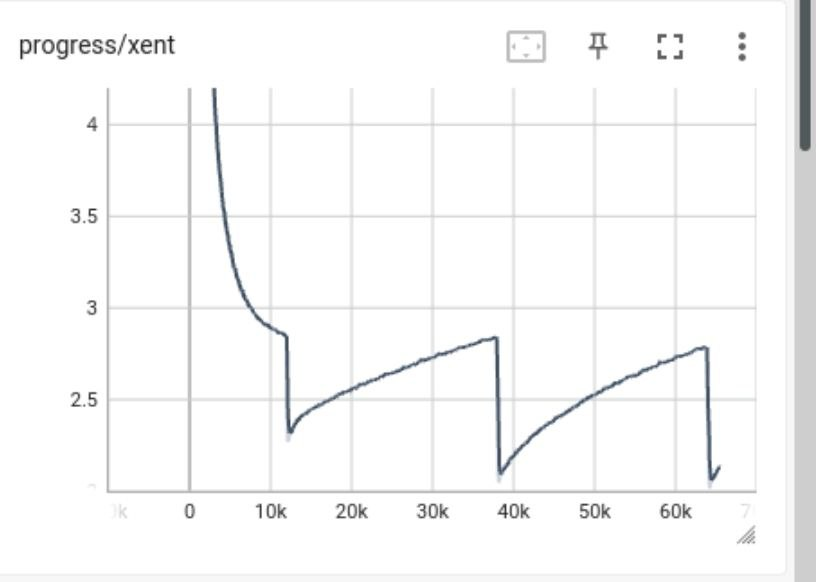
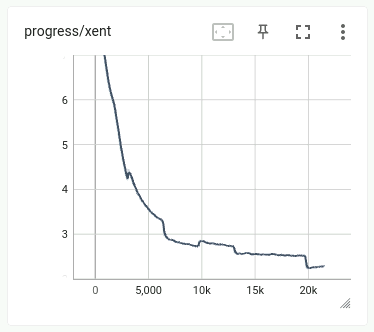
In the process of training models, when using CCMatrix v1 text corpora, I encountered strange behavior; many graphs in tensorboard began to look like a saw. There were also strange things with drawdowns and sharp improvements in the quality of models during the training process.
Turning to the work CCMatrix: Mining Billions of High-Quality Parallel Sentences on the Web - 2021.acl-long.507.pdf I discovered that Meta used LASER to search for original-translation pairs.
Each such pair was assigned a SCORE (every archive with OPUS has such a file with a list) and in the OPUS text corpora the sentences were ranked from the best match to the worst. And indeed, towards the end of the files, the translations became less accurate and often were not even translations at all.
Taking into account the above, as well as the results of model training, I came to the following conclusions:
Errors such as poor-quality translation or complete inconsistency of sentences cannot be easily filtered; it is only possible to form part of the text corpora according to some threshold value.
Many offers, even of poor quality, still provide fairly high-quality models.
Models with a large number of parameters turned out to be more resistant to low quality (Transformer BIG)
A large number of such low-quality sentences sometimes lead to “hallucinations” during translation (subjective assumption).
Now, when training a new model (RU-EN, third attempt in the fight for quality), I try the following option:
I take the first 20% of the entire corpus (with the best expected quality).
Fascinating results! Is the saw tooth pattern because model performance decreases when it’s training on the CCMatrix data with the lowest scores?
I’ve generally not used CCMatrix data because I’ve also had poor results using it. Maybe it would be useful to create a new “CCMatrix Select” dataset that only has the top 20% of translations like you’re doing here.
Yeah, so far I’m assuming that’s what’s happening. Recently in Locomotive (thank you very much, it is very useful) the BLEU estimation has been added during model training.
That’s when I noticed the following cycle:
progress ppl goes up, then drops sharply (i.e. bad sentences end and good ones start again).
BLEU score drops sharply, then starts to rise again to the same level or a little more.
The cycle repeats again.
I can’t open the rest of the charts now, because I have put the model to be trained again.
I will be able to say exactly what effect the cutoff of sentences with low LASER SCORE had later, when the model finishes training.
p.s. I think the full size of the CCMatrix corpus may be useful for low-resource languages or for back-translation data, but for resource-rich languages it may make sense to use only the best part, we’ll see the results.
In this case I did not continue the training, I started a new one. In a couple of days I will report on the result I got.
p.s. by the way, about Locomotive, I left some issues on github. Unfortunately I couldn’t run the latest version of Locomotive on a big corpora and also there is no possibility to assign different weights to different datasets.
It also forcibly filters (or goes through filters anyway) and forcibly mixes sentences and merges datasets.
Because of this it is no longer possible to flexibly customize the work with cases.
After finishing training the model and analyzing the results, I came to the following conclusions:
The indicated nuances concern the CCMatrix and NLLB v1 datasets
Not everything is so clear with the quality of the first 20% of the case, namely:
Yes, the best scores are for sentences at the beginning of the corpus, but as a rule these are simple and relatively short sentences (which is logical, they are easier to evaluate and assign a high similarity score).
The Progress/ppl metric (Tensorboard) quickly becomes low, but this means that the model copes very well with these texts and no longer assimilates new data.
Adding data with an average LASER score from the middle of the dataset sharply increases Progress/ppl (Tensorboard) and at the same time BLEU and valid/ppl begin to increase sharply, which indicates that the model is starting to learn new data.
At the end of the dataset there are pairs of sentences with low LASER scores of two types:
Long sentences, often of high quality, but the similarity of which is more difficult to assess due to their size.
Short, low-quality sentences.
The most effective option for me was trimming the first and last 10% of the corpus with filtering by the length of sentences of 40 characters or more, followed by Shuffling, resulting in 70M pairs of sentences out of 150M. With this filtering, it was possible to achieve the highest quality of the model (I tried options with final dataset sizes of 28M, 56M, 70M, 150M).
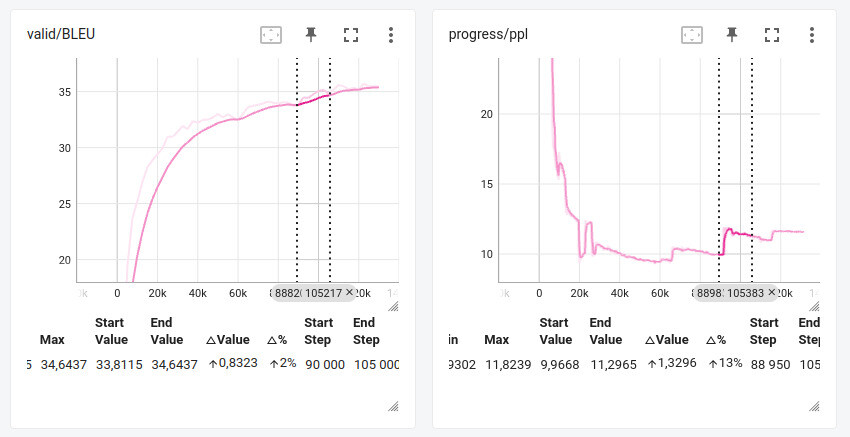
Below is a graph showing the Progress/ppl and valid/BLEU dependencies.
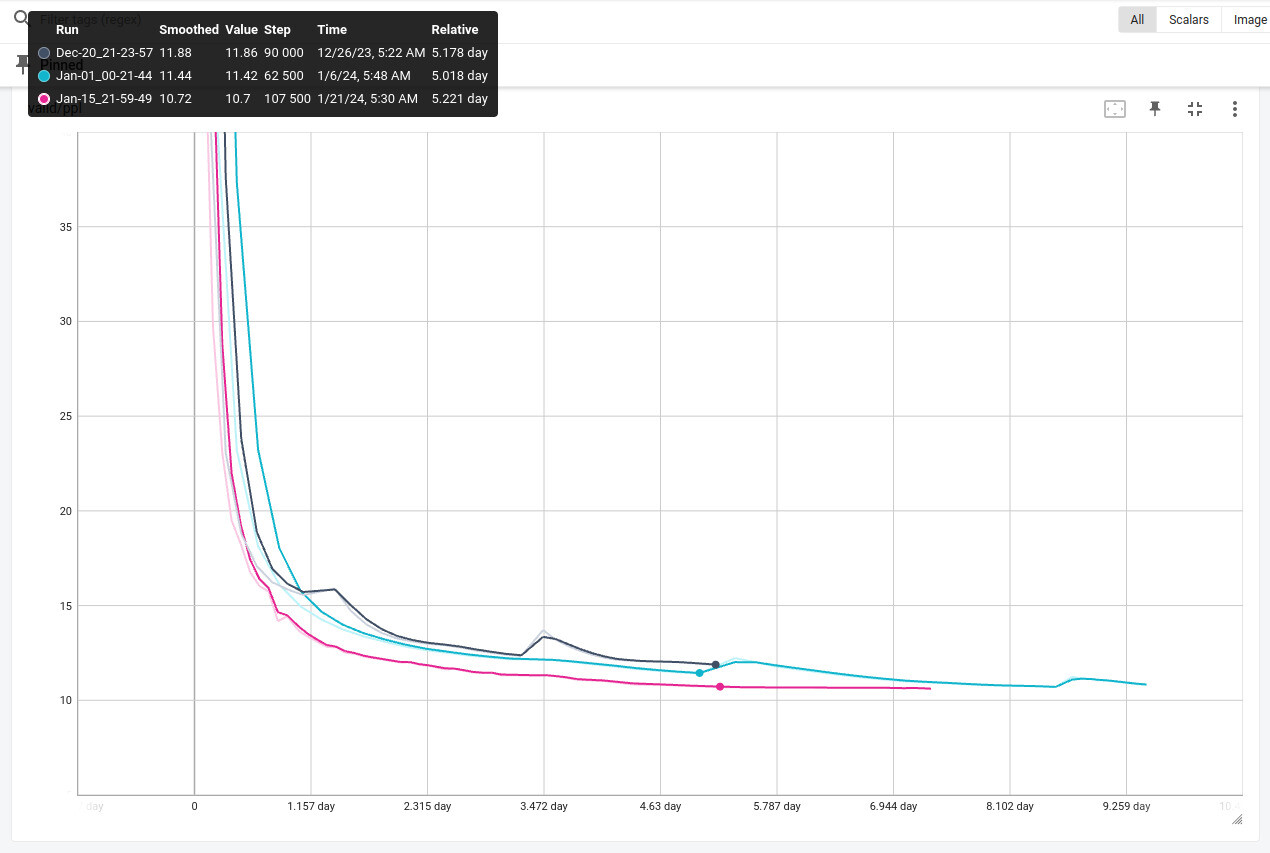
The graph below shows valid/ppl data for three models (lower value is better, direct correlation with quality):
Black color: Model Transformer Base (64M) dataset is not shuffled, the influence of changes in LASER score is visible in the form of cyclical changes in ppl.
Blue color: Model Transformer BIG (209M) dataset is not shuffled, the influence of changes in LASER score is visible in the form of cyclical changes in ppl, but the model is more stable.
Red color: Transformer Deep model (160M) dataset is shuffled and filtered, it is clear that training is more uniform and achieves good quality indicators faster. (I’ll describe the model parameters separately in another topic)
Below is an excerpt from the README.txt file of the NLLB v1 dataset:
Data Fields
Every instance for a language pair contains the following fields: ‘translation’ (containing sentence pairs), ‘laser_score’, ‘source_sentence_lid’, ‘target_sentence_lid’, where ‘lid’ is lang>
As you published, using the top 10% of CCMatrix (among others), the model converges very fast to under 10% ppl, and learns very little afterwards. My only solace is the absence of a regression…
So I am currently pulling out an “excerpt” filter (broadly elaborated from the recent “top” filter) that should work on Locomotive to skip the top and the bottom of a dataset.
Uses arguments “top_percentile” and “bottom_percentile” in filters.py, and adds a parameter “begin_at” in train.py on top of the already existing “stop_at”.
Just have to test it on a toy session as soon as the current one finishes (VRAM is maxing).
It is important to note that, based on my observations, the scores provided by CCMatrix are not consistently reliable. At least for the language pair I am famaiiar in (English-Chinese), this is far from the case. Whether I assess the alignment quality manually as a proficient speaker, or use the embedding model to calculate the cosine similarity of CCMatrix data, the results show that: The scores provided by CCMatrix are highly unreliable, at least for some languages.
Since I am only proficient in English and Chinese, I cannot comment on the performance in other languages. However, I believe it is important to caution against relying too heavily on CCMatrix scores. It is advisable to conduct some sampling and use additional methods to evaluate the data, such as consulting LLM assistants (e.g., ChatGPT, Gemini), mature commercial translation services (Google Translate, DeepL), or feedback from proficient users of the target language. These methods can help determine whether CCMatrix data should be used, and how best to filter it.