I plan to do a model tomorrow for Serbo-Croatian <> English following the new tutorial video that went up that was very useful:
My question is, after I train the model, and assuming it’s added to the official Argos-Train models, how can it be added to the LibreTranslate frontend? Or the LibreTranslate API in general? I can just copy the instructions from the video to train the model (I can also put it up on a dataserver), but to get it added to LibreTranslate from that point is still murky to me (didn’t find any docs on it anywhere), thanks and love the modules!
Currently LibreTranslate downloads and installs all of the Argos Translate models by default; so if a model is on the Argos Translate package index it will be available in a new LibreTranslate installation. The current limiting factor is less training the models and more the bandwidth to download them all on installation. All of the Argos Translate models combined are around 7GB which is a lot to download. If you submit a model we can probably include it but at some point we’ll probably need to decide which models to include in the default installation.
If you want more control of the models in your installations you can use a custom package index with the ARGOS_PACKAGE_INDEX environment variable. You can also set the packages to download with LibreTranslate’s --load-only en,de,fr,es,it option.
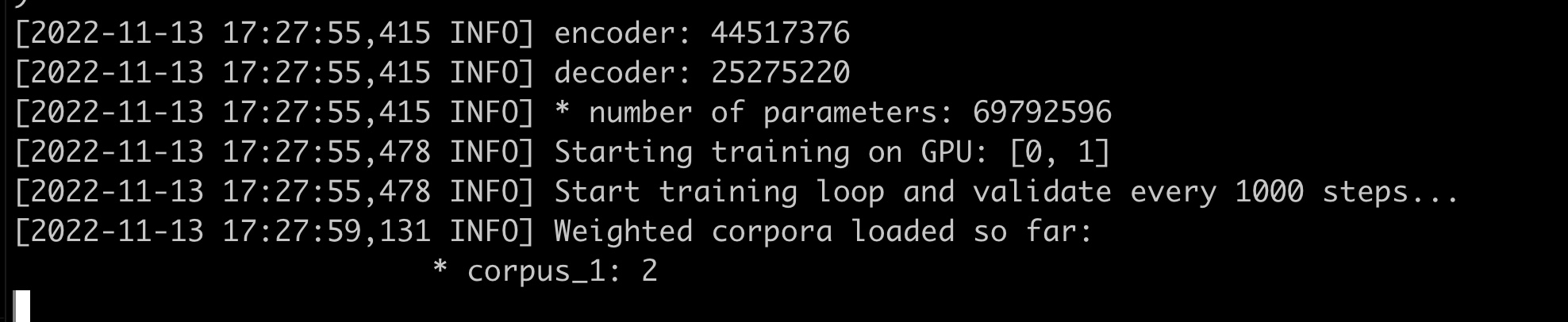
Hi thanks, I was able to get a model trained and installed, though I only did 10,000 training steps as I wanted to try it out and 50k was taking too long. Which makes me wonder, I have a server from Vast with 4 GPU but it seems it was running argos-train only on one, is there way to run OpenNMT with all four GPUs at once? Didn’t see it mentioned anywhere in the docs, thanks!
I had tried that earlier without much success, have you been able to run argos-train on multiple GPUs on Vast before? I am running it just via $ argos-train and then entering in the values manually
But I was able to train a Serbian model which was cool, my only issue is that for the 50k training steps it was looking at about 18 hours on a single GPU which is a bit time prohibitive for me since I would like to train a few models and compare them against eachother, hence why for me it would be great if I could halve or quarter the time by using a Vast server with more than a single GPU.
In my experience OpenNMT-py training in Argos Train by train steps normally progresses like this:
5k → Decent
10k → Good (sometimes 10k works best for languages without much data because it’s less likely to overfit)
20k → Close to maxed out
35k → Often OpenNMT-py will stop early here because performance is no longer improving on the validation dataset.
50k → Very good - this is the default in Argos Train’s config.yml.
100k → This is the default in the OpenNMT-py example but I’ve rarely trained models this long.